
Incident IQ Knowledge Base: Imagine a meticulously crafted resource, a digital sanctuary where solutions to IT’s most pressing challenges reside. This isn’t just a database; it’s a living, breathing ecosystem of information, constantly evolving to meet the ever-changing demands of a dynamic technological landscape. We delve into the architecture, functionality, and strategic implementation of this critical knowledge hub, exploring its core components and the multifaceted strategies for its successful deployment and ongoing maintenance.
From its intricate HTML structure to its robust security protocols, we uncover the secrets behind building a truly effective Incident IQ Knowledge Base.
This exploration covers the crucial aspects of structuring and organizing your Incident IQ knowledge base for optimal efficiency. We’ll examine the best practices for content creation and management, ensuring accuracy and timeliness, and explore methods for enhancing searchability and user experience. We’ll also delve into the integration capabilities with other systems, providing a comprehensive overview of how to leverage this powerful tool to its fullest potential.
Security and scalability considerations are paramount, and we’ll address these critical elements in detail, ensuring your knowledge base remains secure, robust, and readily accessible.
Defining “Incident IQ Knowledge Base”
An Incident IQ Knowledge Base is a centralized repository of information designed to support the efficient resolution of incidents and improve overall IT operational efficiency. It acts as a single source of truth, providing readily accessible information to both IT support staff and end-users, thereby reducing resolution times and improving the overall user experience. This contrasts with a scattered approach where information is stored across various documents, emails, and individuals, leading to inefficiencies and inconsistencies.The core components of an Incident IQ knowledge base typically include articles, FAQs, troubleshooting guides, and potentially videos or other multimedia resources.
A robust search functionality is crucial for quick access to relevant information. Effective organization through categorization and tagging is also essential for easy navigation and retrieval. Furthermore, robust reporting and analytics features can provide insights into common incident types, enabling proactive problem-solving and knowledge base improvement.
Core Components of an Incident IQ Knowledge Base
A well-structured Incident IQ knowledge base is comprised of several key elements working in concert to provide comprehensive support. These components ensure that information is readily accessible, easily searchable, and consistently updated. The effectiveness of these components directly impacts the efficiency of incident resolution and the overall user experience.
- Articles: Detailed, step-by-step guides addressing specific issues or processes. These articles may cover complex troubleshooting steps, software configuration details, or system maintenance procedures. For example, an article might detail the process for resetting a user’s password, including screenshots to illustrate the steps.
- FAQs (Frequently Asked Questions): Concise answers to common questions from end-users. These are often organized by topic or product, allowing users to quickly find answers to simple problems without needing to contact support. For example, a FAQ section might address common printer issues, such as paper jams or connectivity problems.
- Troubleshooting Guides: Structured guides that walk users through a series of diagnostic steps to identify and resolve technical problems. These guides often use a decision-tree approach, guiding the user based on their responses. A troubleshooting guide might help a user determine the cause of slow internet speeds by checking network connectivity, router settings, and other potential issues.
- Multimedia Resources: Videos, screencasts, and images can enhance understanding and provide visual aids to support textual instructions. For example, a video might demonstrate how to connect a new device to a network, clarifying complex steps.
- Search Functionality: A robust search engine allows users to quickly locate relevant information based on s or phrases. This is critical for efficient knowledge base usage. A good search engine should utilize advanced techniques like stemming and synonym matching to ensure accurate results.
Purpose and Benefits of a Well-Structured Incident IQ Knowledge Base
The primary purpose of an Incident IQ knowledge base is to empower users and IT staff to resolve incidents quickly and efficiently. This reduces the burden on support teams, improves user satisfaction, and minimizes downtime. A well-structured knowledge base contributes significantly to the overall effectiveness of IT operations.
- Reduced Resolution Times: By providing readily available solutions, the knowledge base allows users and IT staff to resolve issues independently, reducing the time spent waiting for support.
- Improved User Satisfaction: Empowered users who can quickly find answers to their questions experience improved satisfaction with IT services.
- Increased IT Team Efficiency: By reducing the number of support tickets, the knowledge base frees up IT staff to focus on more complex tasks.
- Reduced Costs: The efficiency gains translate into reduced operational costs associated with incident resolution.
- Improved Knowledge Sharing: The knowledge base facilitates the sharing of best practices and expertise across the IT team.
Types of Information Stored Within an Incident IQ Knowledge Base
The information stored within an Incident IQ knowledge base varies depending on the organization’s needs and the types of incidents it typically handles. However, some common categories include information on software applications, hardware devices, network infrastructure, security protocols, and internal processes.
- Software Application Information: Details on software installations, configurations, troubleshooting, and updates. This might include version numbers, known bugs, and workarounds.
- Hardware Device Information: Specifications, troubleshooting guides, and maintenance procedures for various hardware components. This might include information on printers, computers, servers, and network devices.
- Network Infrastructure Information: Documentation on network topology, IP addresses, DNS settings, and security measures. This information is crucial for network troubleshooting and maintenance.
- Security Protocols and Policies: Information on security best practices, password policies, and incident response procedures. This helps maintain a secure IT environment.
- Internal Processes and Procedures: Documentation of internal IT processes, such as ticket handling, change management, and incident reporting. This ensures consistency and efficiency in IT operations.
Content Organization and Structure
Effective organization and structuring of an Incident IQ knowledge base is crucial for efficient information retrieval and user experience. A well-designed system ensures that users can quickly find solutions to their problems, minimizing downtime and improving overall operational efficiency. This section details the design considerations for content organization within the knowledge base.
HTML Table Structure
The following HTML table provides a sample representation of the Incident IQ knowledge base. This structure allows for clear presentation of incident details in a responsive format, adaptable to various screen sizes. Basic CSS styling enhances readability.
<table style="font-size: 14px; border-collapse: collapse; width: 100%;">
<thead>
<tr>
<th style="padding: 8px; border: 1px solid #ddd; text-align: left;">Incident Type</th>
<th style="padding: 8px; border: 1px solid #ddd; text-align: left;">Description</th>
<th style="padding: 8px; border: 1px solid #ddd; text-align: left;">Resolution Steps</th>
<th style="padding: 8px; border: 1px solid #ddd; text-align: left;">Related Articles</th>
</tr>
</thead>
<tbody>
<tr>
<td>Network Outage</td>
<td>Complete loss of network connectivity.</td>
<td>
<ul>
<li>Check network cables.</li>
<li>Restart router and modem.</li>
<li>Contact IT support.</li>
</ul>
</td>
<td>Article ID: 123, 456</td>
</tr>
<tr>
<td>Printer Error</td>
<td>Printer failing to print.</td>
<td>
<ul>
<li>Check paper tray.</li>
<li>Check ink levels.</li>
<li>Restart printer.</li>
</ul>
</td>
<td>Article ID: 789</td>
</tr>
<tr>
<td>Software Crash</td>
<td>Application unexpectedly closes.</td>
<td>
<ul>
<li>Check for updates.</li>
<li>Restart application.</li>
<li>Reinstall application.</li>
</ul>
</td>
<td>Article ID: 101</td>
</tr>
<tr>
<td>Security Breach</td>
<td>Suspected unauthorized access.</td>
<td>
<ul>
<li>Change passwords.</li>
<li>Report to security team.</li>
<li>Review security logs.</li>
</ul>
</td>
<td>Article ID: 102, 103</td>
</tr>
<tr>
<td>Hardware Failure</td>
<td>Computer not powering on.</td>
<td>
<ul>
<li>Check power supply.</li>
<li>Check power cord.</li>
<li>Contact IT support.</li>
</ul>
</td>
<td>Article ID: 104</td>
</tr>
</tbody>
</table>
Hierarchical Structure Design
A hierarchical structure facilitates efficient categorization and navigation of incident information. The following nested JSON object represents a sample hierarchical structure for the knowledge base. Each level provides increasing specificity, allowing for targeted searches and easier maintenance.
"Network": // Top-level category: Network-related incidents
"Connectivity Issues": // Subcategory: Problems with network connectivity
"Wireless Connectivity": [], // Lower-level category: Specific issue within subcategory
"Wired Connectivity": [],
"VPN Connectivity": []
,
"DNS Problems": // Subcategory: Issues related to Domain Name System
"DNS Resolution Failures": [],
"DNS Server Unreachable": [],
"DNS Configuration Errors": []
,
"Firewall Issues": // Subcategory: Problems with network firewalls
"Firewall Rule Conflicts": [],
"Firewall Port Blocking": [],
"Firewall Access Denied": []
,
"Hardware": // Top-level category: Hardware-related incidents
"Printer Problems":
"Paper Jams": [],
"Ink Cartridge Issues": [],
"Printer Driver Errors": []
,
"Laptop Issues":
"Battery Problems": [],
"Overheating": [],
"Hardware Failures": []
,
"Desktop Issues":
"Boot Problems": [],
"Peripheral Issues": [],
"Operating System Errors": []
,
"Software": // Top-level category: Software-related incidents
"Application Errors":
"Application Crashes": [],
"Application Freezes": [],
"Application Performance Issues": []
,
"Operating System Issues":
"OS Crashes": [],
"OS Updates": [],
"OS Configuration Errors": []
,
"Software Licensing":
"License Activation": [],
"License Expiration": [],
"License Key Issues": []
,
"Security": // Top-level category: Security-related incidents
"Security Breaches":
"Unauthorized Access": [],
"Data Breaches": [],
"Malware Infections": []
,
"Account Issues":
"Password Resets": [],
"Account Lockouts": [],
"Account Compromises": []
,
"Phishing Attempts":
"Email Phishing": [],
"Website Phishing": [],
"Smishing": []
Tagging and Indexing System
A robust tagging and indexing system enhances searchability and discoverability within the knowledge base. Tags will be stored in a JSON array associated with each article. Tags will be assigned manually by administrators, allowing for precise categorization and control over the tagging process.
// Sample JSON array for tags
[
"articleID": 123, "tags": ["network outage", "connectivity", "router", "modem"],
"articleID": 789, "tags": ["printer", "hardware", "paper jam", "ink"]
]
The following pseudocode Artikels an algorithm for retrieving articles based on multiple tag searches using AND, OR, and NOT operators:
function searchArticles(query, articles)
let results = [];
let tags = query.split(" "); // Split query into individual tags
let operators = ["AND", "OR", "NOT"];
let tagWeights = ; //Initialize tag weights (can be pre-defined or learned)
//Assign weights to tags (example)
tagWeights["network outage"] = 5;
tagWeights["printer"] = 3;
//Add more weights
for (let article of articles)
let matchCount = 0;
let notMatch = false;
for (let tag of tags)
let operator = "AND"; //Default operator
if(operators.some(op => tag.includes(op)))
let parts = tag.split(/(AND|OR|NOT)/);
tag = parts[0];
operator = parts[1];
if (operator === "NOT" && article.tags.includes(tag))
notMatch = true;
break;
else if (operator === "OR" && article.tags.includes(tag))
matchCount++;
break; // OR operator only requires one match
else if (operator === "AND" && article.tags.includes(tag))
matchCount++;
if (!notMatch && (query.includes("OR") ? matchCount > 0 : matchCount === tags.length) )
let score = 0;
for(let t of article.tags)
score += tagWeights[t] || 1; //Give a default weight if not found
results.push( article, score );
// Rank results based on score
results.sort((a, b) => b.score - a.score);
return results.map(r => r.article);
Search Functionality (Pseudocode)
The following pseudocode describes a search function that prioritizes articles based on matches and tag weights:
function search(query)
// Tokenize the query into s
s = tokenize(query);
// Initialize an empty ranked list of articles
rankedArticles = [];
// Iterate through all articles in the knowledge base
for each article in knowledgeBase
// Calculate a relevance score based on matches in title, description, and tags
score = calculateRelevanceScore(article, s);
// Add the article to the ranked list with its score
rankedArticles.push( article, score );
// Sort the ranked list in descending order based on relevance score
rankedArticles.sort((a, b) => b.score - a.score);
// Return the top N articles from the ranked list
return rankedArticles.slice(0, N);
function calculateRelevanceScore(article, s)
// Initialize the relevance score
score = 0;
// Add points for matches in the title
for each in s
if title.contains()
score += titleWeight;
// Add points for matches in the description
for each in s
if description.contains()
score += descriptionWeight;
// Add points for matches in the tags, weighted by tag importance
for each tag in article.tags
for each in s
if tag.contains()
score += tagWeight
- tagImportance(tag);
// Return the calculated relevance score
return score;
Error Handling (Description)
The system will implement comprehensive error handling to gracefully manage various scenarios. Missing articles will return a “404 Article Not Found” error message. Invalid tags will trigger a “Invalid Tag” error, prompting the user to review their input. Empty search queries will result in a “Please enter a search query” message. All errors will be logged with timestamps and relevant details for debugging purposes using a centralized logging system.
Data Validation (Schema)
A JSON schema will be used to validate the structure and data types of incident information. This ensures data integrity and consistency.
"type": "object",
"properties":
"incidentType": "type": "string", "minLength": 3, "maxLength": 50,
"description": "type": "string", "maxLength": 100,
"resolutionSteps": "type": "array", "items": "type": "string",
"relatedArticles": "type": "array", "items": "type": "integer"
,
"required": ["incidentType", "description", "resolutionSteps"]
Valid Example:
"incidentType": "Network Outage",
"description": "Complete loss of network connectivity.",
"resolutionSteps": ["Check network cables.", "Restart router and modem.", "Contact IT support."],
"relatedArticles": [123, 456]
Invalid Example (missing required field):
"description": "Printer failing to print.",
"resolutionSteps": ["Check paper tray.", "Check ink levels."]
Content Creation and Management
Effective content creation and management are crucial for a successful Incident IQ knowledge base. A well-structured and regularly updated knowledge base empowers users to resolve issues independently, reducing reliance on support teams and improving overall operational efficiency. This section details strategies for content creation, ensuring accuracy and timeliness, and establishing a robust governance model.
Content Examples for Incident IQ Knowledge Base
The following examples illustrate diverse content types suitable for an Incident IQ knowledge base, tailored to different user needs and skill levels. Each example leverages Incident IQ’s functionalities to provide practical and relevant information.
| Content Type | Example Topic | Target Audience | Key Characteristics |
|---|---|---|---|
| Frequently Asked Questions (FAQs) | Why is my Incident IQ dashboard displaying incomplete incident data? | All users | Concise, numbered answers; easily searchable using s like “dashboard,” “incomplete data,” and “Incident IQ.” Each answer should directly address the question and offer clear, actionable steps or explanations. For example, a solution might involve verifying API connections or checking data synchronization settings within Incident IQ. |
| Troubleshooting Guides | Resolving “Authentication Failed” errors when accessing Incident IQ | Technical users, administrators | Step-by-step instructions, screenshots illustrating each step, and a list of potential error codes (e.g., 401, 403). The guide should cover common causes of authentication failures, such as incorrect credentials, network connectivity issues, and browser caching problems, with specific solutions for each. |
| Best Practices Guides | Optimizing Incident IQ alert configurations for efficient incident response | Administrators, power users | Actionable tips and clear recommendations based on best practices for alert management within Incident IQ. This could include strategies for defining alert thresholds, configuring notification channels (email, SMS, etc.), and prioritizing alerts based on severity and impact. The guide should provide data-driven insights into how these optimizations improve response times and reduce alert fatigue. |
| How-to Guides | Integrating Incident IQ with external monitoring tools | Administrators, analysts | Detailed instructions with screenshots or screen recordings demonstrating the integration process step-by-step. This guide should cover specific integration methods for popular monitoring tools, including configuration settings, API keys, and potential troubleshooting steps. Examples could include integration with PagerDuty, Datadog, or Splunk. |
| Case Studies | Successful reduction in mean time to resolution (MTTR) using Incident IQ’s automated workflows | All users | A narrative format detailing a specific scenario where Incident IQ’s automation features were used to resolve incidents more efficiently. This should highlight the key benefits and outcomes, such as reduced MTTR, improved team collaboration, and increased operational efficiency. Quantifiable results (e.g., percentage reduction in MTTR) should be included. |
Accuracy and Timeliness Strategies
Maintaining the accuracy and timeliness of the knowledge base requires a proactive approach. Three key strategies, along with measurable metrics, are Artikeld below.
Implementing these strategies ensures the knowledge base remains a reliable and up-to-date resource for all users. Regular monitoring of these metrics allows for iterative improvements in content management.
- Scheduled Reviews and Updates: All articles are reviewed and updated on a pre-defined schedule. For example, FAQs might be reviewed monthly, while troubleshooting guides and how-to guides are reviewed quarterly. Best practices and case studies could be updated annually. Metric: Number of articles updated per quarter. Implementation: Create a content calendar outlining review schedules for each article type. Assign responsibility for each review.
- User Feedback Mechanism: Integrate a feedback mechanism (e.g., ratings, comments, or a dedicated feedback form) within each knowledge base article. This allows users to report inaccuracies or suggest improvements. Metric: Number of user feedback responses received and addressed per month. Implementation: Embed a feedback form at the end of each article. Establish a process for reviewing and responding to user feedback.
- Automated Data Synchronization: Where possible, automatically synchronize information from Incident IQ’s internal data sources (e.g., configuration settings, API documentation) into the knowledge base. This ensures that the knowledge base always reflects the current state of the system. Metric: Percentage of knowledge base content automatically updated. Implementation: Develop scripts or integrations to pull relevant data from Incident IQ’s internal APIs and update the knowledge base automatically.
Knowledge Base Article Review and Update Process
A structured review and update process is essential for maintaining the knowledge base’s quality and relevance.
This process ensures that all articles are current, accurate, and meet the established standards for clarity and completeness. Regular reviews and updates are crucial for maintaining user trust and maximizing the value of the knowledge base.
- Frequency of Review: FAQs (monthly), Troubleshooting Guides (quarterly), Best Practices Guides (annually), How-to Guides (quarterly), Case Studies (annually).
- Review Team: Subject Matter Experts (SMEs) responsible for the accuracy of technical information; Technical Writers responsible for clarity and style; Editors responsible for overall quality and consistency.
- Update Criteria: Outdated information, user feedback indicating inaccuracies or omissions, changes in Incident IQ functionality or features, significant changes in best practices, and low user engagement metrics (e.g., low views, high bounce rates).
- Version Control: Use a version control system (e.g., Git) to track changes and maintain previous versions of articles. This allows for easy rollback if necessary.
- Workflow:
- SME reviews the article for technical accuracy.
- Technical Writer reviews for clarity, style, and consistency.
- Editor performs a final review for overall quality and compliance with style guidelines.
- Approved article is updated in the knowledge base.
- Version history is updated in the version control system.
Content Governance
A robust governance model ensures consistency, accuracy, and high-quality content across the entire knowledge base.
Consistent style and tone enhance readability and user experience, while a clear approval process ensures accuracy and relevance. Clearly defined content ownership ensures accountability and efficient maintenance.
- Style Guide: A comprehensive style guide should be created and maintained, covering aspects such as writing style, terminology, formatting conventions (headings, lists, tables), and voice and tone. This style guide should be easily accessible to all content creators.
- Content Approval Process: A three-step approval process involving SMEs, technical writers, and editors, as described in the previous section, ensures quality control and consistency.
- Content Ownership: Assign ownership of specific content areas (e.g., FAQs, troubleshooting guides) to responsible individuals or teams. This ensures accountability for the accuracy and timeliness of information within those areas. A content ownership matrix can be created to clearly define responsibilities.
User Interaction and Search
Effective user interaction and robust search functionality are crucial for a successful Incident IQ knowledge base. A well-designed interface ensures users can quickly find the information they need, reducing resolution times and improving overall efficiency. This section details strategies for optimizing both the search experience and the overall user interface.
User Interface Design for Search and Navigation
The user interface should prioritize intuitive navigation and efficient searching. A prominent search bar, easily accessible on every page, is essential. The search should support both and full-text searches, with auto-suggestions appearing as the user types to aid in refining their query. Results should be displayed clearly, with relevant metadata such as article title, author, last updated date, and a brief summary to help users quickly assess relevance.
Facets or filters (e.g., by category, tags, or date) can significantly improve search refinement. Clear visual hierarchy and consistent design elements throughout the knowledge base will improve usability. Consider incorporating a breadcrumb trail to show the user’s current location within the knowledge base hierarchy. For example, a user searching for “network outage” might see results filtered by category (“Network Issues”), with each result showing a snippet of text containing the search term, along with metadata such as author and last updated date.
Methods for Improving Searchability
Improving the searchability of the knowledge base content involves optimizing both the content itself and the search engine behind it. Content should be structured logically, using clear and concise language. The use of relevant s and tags is vital, as is the consistent application of a controlled vocabulary. The knowledge base should leverage metadata, including tags, categories, and custom fields, to improve the accuracy of search results.
Regular updates to the search engine’s indexing process will ensure that new content is quickly discoverable. Implementing techniques such as stemming (reducing words to their root form) and synonym handling can broaden the scope of searches. For example, a search for “firewall problem” should also return results containing “firewall issue” or “firewall malfunction”. Regular analysis of search queries and user feedback can reveal areas for improvement in both content and search functionality.
This iterative process of improvement is critical for maintaining a highly effective knowledge base.
Personalizing the User Experience
Personalization can significantly enhance the user experience. Role-based access control (RBAC) can restrict access to sensitive information based on user roles (e.g., only administrators can access internal documentation). Personalized dashboards could display frequently accessed articles or those relevant to a user’s role. Recommendations based on past searches or browsing history could also be implemented. For instance, a help desk agent might see a personalized dashboard featuring articles related to common customer issues, while a system administrator might see articles on server maintenance.
User profiles could allow for customization of display settings, such as font size or preferred language. A system for user feedback, allowing users to rate articles and suggest improvements, would continuously improve the knowledge base’s relevance and accuracy. This personalized approach ensures that users find the information they need quickly and efficiently, contributing to a more productive workflow.
Integration with Other Systems
Effective integration of the Incident IQ knowledge base with other systems is crucial for optimizing incident response and minimizing redundancy. Seamless data flow between the knowledge base and other incident management tools enhances efficiency and improves the overall effectiveness of incident resolution. This integration facilitates a centralized repository of knowledge, readily accessible to all relevant personnel.
Successful integration requires a strategic approach considering the specific functionalities and APIs of both the knowledge base and the target systems. This involves careful planning, robust testing, and ongoing maintenance to ensure data accuracy and system stability. Different integration methods offer varying levels of complexity and automation, allowing organizations to tailor their approach to their specific needs and technical capabilities.
API-Driven Data Exchange
Leveraging APIs (Application Programming Interfaces) is a fundamental aspect of integrating the Incident IQ knowledge base with other systems. APIs allow for automated and secure data exchange, eliminating manual data entry and reducing the potential for errors. For example, an API can be used to automatically populate the knowledge base with frequently asked questions (FAQs) extracted from customer support tickets in a CRM system.
Conversely, the knowledge base can push relevant articles to incident management systems, providing technicians with immediate access to troubleshooting guides during an active incident. This bidirectional data flow ensures that the knowledge base remains up-to-date and readily available. Specific API endpoints would need to be defined to handle operations like creating, updating, and retrieving knowledge base articles.
The choice of API protocol (e.g., REST, GraphQL) will depend on the capabilities of both systems.
Automated Knowledge Base Updates from Incident Data
Automating the update of knowledge base articles based on incident data from other systems streamlines the knowledge management process. This automation can be achieved by configuring triggers within the incident management system that automatically generate new knowledge base articles or update existing ones based on predefined criteria. For instance, if a particular incident resolution requires multiple steps and involves a unique solution, the system can automatically create a new knowledge base article detailing this process.
Similarly, if a specific error message repeatedly appears in incident reports, the system could automatically update the corresponding knowledge base article with new information or troubleshooting steps. This automated approach reduces manual effort and ensures the knowledge base reflects the latest incident resolution techniques and best practices. The implementation would involve defining rules and conditions within the incident management system that trigger the article creation or update processes.
These rules could be based on incident severity, frequency, or specific error codes.
Integration with Incident Management Tools
Integrating the Incident IQ knowledge base with various incident management tools like ServiceNow, Jira Service Desk, or PagerDuty significantly improves the efficiency of incident response. This integration allows technicians to access relevant knowledge base articles directly within their incident management dashboards. For example, when a technician opens an incident ticket in ServiceNow, the system could automatically display relevant knowledge base articles based on s or categories related to the incident description.
This contextual information helps technicians quickly identify potential solutions and resolve incidents more efficiently. The integration process usually involves configuring the incident management tool to connect with the knowledge base’s API or using pre-built integrations available through the marketplace of the respective platforms. This integration requires careful configuration to ensure data synchronization and avoid conflicts.
Knowledge Base Metrics and Reporting

Effective knowledge base management requires a robust system for tracking performance and user engagement. By monitoring key metrics, organizations can identify areas for improvement, optimize content, and demonstrate the value of the knowledge base to stakeholders. This section Artikels key performance indicators (KPIs), reporting strategies, and feedback mechanisms for assessing knowledge base effectiveness.
Key Performance Indicators (KPIs) for Knowledge Base Effectiveness
Several KPIs can be used to gauge the success of a knowledge base. These metrics provide a comprehensive understanding of its impact on user experience, problem resolution, and overall efficiency. Careful selection and monitoring of these KPIs are crucial for continuous improvement.
- Search Success Rate: This measures the percentage of searches that result in the user finding a relevant and helpful article. A high success rate indicates effective content organization and search functionality. For example, a success rate of 80% suggests that four out of five searches lead to a satisfactory outcome.
- Average Resolution Time: This KPI tracks the average time it takes users to resolve their issues using the knowledge base. A shorter average resolution time indicates improved efficiency and a more user-friendly knowledge base. A reduction from 15 minutes to 5 minutes signifies a significant improvement.
- Knowledge Base Article Views: The total number of times articles are viewed provides insight into content popularity and user needs. High views on specific articles indicate high demand and relevance, while low views might suggest the need for content updates or improved discoverability.
- Number of Searches Performed: This metric indicates the overall usage of the knowledge base. A high number of searches suggests that users are actively utilizing the resource to find answers. A steady increase over time demonstrates growing adoption.
- Customer Satisfaction (CSAT) Score Related to Knowledge Base Use: This measures user satisfaction with the knowledge base’s content and usability. A high CSAT score indicates a positive user experience and effective content. Regular surveys and feedback mechanisms can effectively capture this data.
- First Contact Resolution (FCR) Rate: This metric measures the percentage of issues resolved by users through the knowledge base without requiring additional support from agents. A high FCR rate demonstrates the knowledge base’s ability to empower users to solve their problems independently.
Knowledge Base Usage Statistics Report
A comprehensive report should summarize key usage statistics, providing insights into user behavior and knowledge base performance. This report should be regularly generated (e.g., monthly or quarterly) to track trends and identify areas for improvement.
| Metric | Data Point | Trend | Actionable Insight |
|---|---|---|---|
| Search Success Rate | 78% | Increased by 5% from last quarter | Content optimization and improved search algorithm are working effectively. |
| Average Resolution Time | 7 minutes | Decreased by 2 minutes from last quarter | Improved content clarity and organization are reducing user search time. |
| Knowledge Base Article Views | 15,000 | Increased by 10% from last quarter | High demand for existing content. Consider creating more articles on similar topics. |
| Number of Searches Performed | 5,000 | Increased by 8% from last quarter | Growing user adoption and reliance on the knowledge base. |
| CSAT Score | 4.5 out of 5 | Stable | Users are generally satisfied with the knowledge base. Consider targeted improvements based on feedback. |
| FCR Rate | 65% | Increased by 3% from last quarter | The knowledge base is successfully resolving a higher percentage of issues independently. |
Tracking User Feedback on Knowledge Base Content and Usability
Gathering user feedback is crucial for continuous improvement. Multiple methods can be employed to collect this feedback, providing valuable insights into user experience and content effectiveness.
- In-Article Feedback Forms: Simple forms at the end of each article allow users to rate the helpfulness of the content and provide comments.
- Post-Search Feedback Surveys: Surveys triggered after a search ask users to rate the relevance of the search results and provide suggestions for improvement.
- Regular User Surveys: Periodic surveys assess overall satisfaction with the knowledge base, identifying areas for improvement in content, organization, and search functionality.
- Usability Testing: Observing users interacting with the knowledge base provides valuable qualitative data on usability issues and areas for improvement.
Security and Access Control
Maintaining the integrity and confidentiality of the Incident IQ Knowledge Base is paramount. This section details the security measures implemented to protect data, control access, and ensure compliance with relevant regulations. A multi-layered approach encompassing encryption, role-based access control, access control lists, auditing, intrusion detection, data loss prevention, and vulnerability management is employed.
Data Encryption
The Incident IQ Knowledge Base utilizes robust encryption techniques to safeguard data both at rest and in transit. Data at rest, including knowledge base articles and metadata, will be encrypted using AES-256, a widely recognized and highly secure symmetric encryption algorithm. Data in transit will be protected using TLS 1.3 or later, ensuring encrypted communication between clients and the knowledge base server.
Key management follows a hierarchical approach with key rotation schedules implemented to minimize the impact of potential compromise. Database-level encryption will be implemented to protect the underlying data storage. Keys are managed using a Hardware Security Module (HSM) for enhanced security. Key rotation occurs every 90 days, with old keys securely archived. The encryption and decryption processes leverage industry-standard libraries and APIs, ensuring compatibility and best practices are followed.
Role-Based Access Control (RBAC)
The knowledge base implements a Role-Based Access Control system to manage user permissions. Three primary roles are defined: Administrator, Editor, and Viewer. The following table Artikels the permissions associated with each role:
| Role | Create Articles | Edit Articles | Delete Articles | View Articles | Manage Users |
|---|---|---|---|---|---|
| Administrator | Yes | Yes | Yes | Yes | Yes |
| Editor | Yes | Yes | Yes | Yes | No |
| Viewer | No | No | No | Yes | No |
RBAC is implemented using a combination of database roles and application-level logic. The database utilizes its built-in role-based access control features to manage access to underlying data. The application layer enforces further restrictions based on user roles, ensuring granular control over actions within the knowledge base interface. User roles and permissions are managed through a dedicated administrative interface, providing a centralized location for managing user access.
The process for assigning and revoking roles involves updating the user’s database role and application-level permissions. An audit trail records all changes to user roles and permissions.
Access Control Lists (ACLs)
Beyond RBAC, Access Control Lists (ACLs) provide granular control at the individual article level. ACLs allow administrators to specify which users or groups have access to specific articles, regardless of their assigned role. For instance, a sensitive article containing confidential information could be configured to allow access only to a specific group of authorized personnel, even if those individuals are assigned the “Viewer” role.
The system will support inheritance of ACLs, allowing for efficient management of permissions across articles and folders. This granular control ensures that sensitive information is only accessible to authorized personnel. An example configuration might involve granting read-only access to a specific article to a group of security analysts.
Auditing and Logging
The system maintains detailed security logs to track all security-relevant events. These logs include login attempts (successful and unsuccessful), access to sensitive articles, modifications to articles (creation, update, deletion), changes to user roles and permissions, and any failed access attempts. Logs are stored in a secure, centralized location using a database designed for high-volume logging. Logs are formatted using a structured format (e.g., JSON) for efficient analysis and searching.
Effective incident management hinges on a robust knowledge base, such as that provided by IncidentIQ. However, the seamless integration of all data can be compromised; for instance, refer to the troubleshooting guide addressing the issue of swish not saving to knowledge base for potential solutions. Addressing such technical challenges is crucial for maintaining the integrity and utility of the IncidentIQ knowledge base for future incident response and analysis.
A retention policy of 12 months is implemented, complying with regulatory requirements.
Intrusion Detection and Prevention
To detect and prevent unauthorized access attempts, the knowledge base employs a multi-layered approach. A Web Application Firewall (WAF) filters malicious traffic before it reaches the application server. Regular security scans using automated vulnerability scanners are performed to identify and address potential vulnerabilities. Intrusion detection systems (IDS) monitor network traffic for suspicious activity. A comprehensive incident response plan is in place, outlining procedures for identifying, containing, and remediating security breaches.
This plan includes communication protocols, escalation paths, and post-incident analysis procedures.
Data Loss Prevention (DLP)
Data loss prevention strategies include regular backups of the entire knowledge base, version control to track changes to articles, and disaster recovery planning. Daily backups are performed, with backups retained for 30 days. Weekly backups are stored offsite for disaster recovery purposes. Version control ensures that previous versions of articles are available in case of accidental deletion or modification.
Disaster recovery plans include procedures for restoring the knowledge base from backups in case of system failure or data loss. A failover mechanism is implemented to ensure high availability.
Vulnerability Management
Regular vulnerability scanning is performed using automated tools to identify and address potential security vulnerabilities. The scanning process includes both static and dynamic analysis techniques to cover a wide range of vulnerabilities. Patches and updates are applied promptly after they are released by the vendor. A vulnerability management process is established, ensuring that all identified vulnerabilities are assessed, prioritized, and remediated in a timely manner.
The system utilizes industry-standard tools and methodologies for vulnerability scanning and remediation.
Scalability and Maintainability: Incident Iq Knowledge Base

Ensuring the Incident IQ knowledge base remains accessible, responsive, and secure requires a robust strategy for scalability and maintainability. This encompasses proactive planning for data growth, implementing efficient maintenance procedures, developing a comprehensive migration plan, and integrating robust security measures throughout the lifecycle of the knowledge base. The following sections detail the strategies and plans to address these critical aspects.
Data Scalability Strategies
Effective scaling of the knowledge base is crucial to accommodate increasing data volume and user traffic. This necessitates a multi-faceted approach encompassing both horizontal and vertical scaling techniques, along with predictive modeling for future growth.
Horizontal scaling, achieved through sharding and replication, distributes the database load across multiple servers. We propose utilizing a distributed NoSQL database such as Cassandra, known for its excellent scalability and high availability. Sharding partitions the data across multiple nodes, while replication creates redundant copies across different nodes to ensure data availability and fault tolerance. This architecture allows for seamless handling of increased data volume and user requests without impacting performance.
Vertical scaling involves upgrading server hardware resources, such as increasing RAM, CPU, and storage capacity. This approach is suitable for handling short-term increases in load. To optimize database queries, we will implement query optimization techniques such as indexing, query caching, and the use of read replicas. Key performance metrics, including query response time, CPU utilization, and disk I/O, will be continuously monitored using tools like Prometheus and Grafana.
Alert thresholds (as detailed in Table 1) will trigger notifications to the operations team, enabling proactive intervention to prevent performance degradation.
Predicting data growth over the next three years is essential for capacity planning. We will employ a time-series analysis approach, using historical data on knowledge base article creation, user activity, and incident resolution rates. This methodology allows us to project future data volume and user growth with reasonable accuracy. For instance, if the current growth rate is 20% annually, we can project a three-year growth of approximately 72.8% (1.2 3 ≈ 1.728).
This projection will inform decisions on hardware upgrades and database scaling strategies.
Knowledge Base Maintenance
A robust maintenance plan is vital for ensuring data integrity, availability, and performance. This involves regular backups, controlled updates, and a process for handling obsolete information.
Regular backups are scheduled for every 24 hours, employing a differential backup strategy. This approach minimizes storage space requirements while enabling quick restoration. Backups are retained for 30 days on a secondary, geographically separate cloud storage location (e.g., AWS S3 or Azure Blob Storage). Encryption is implemented both in transit and at rest, ensuring data confidentiality. Table 1 provides target values and monitoring thresholds for various metrics related to backup operations.
Knowledge base updates will follow a version control system (e.g., Git) to track changes and enable rollback if necessary. A comprehensive testing strategy, including unit and integration tests, will be implemented before deployment. A phased rollout approach will minimize disruption to users. In case of errors, a rollback plan is in place, allowing quick reversion to the previous stable version.
Obsolete information will be flagged by designated knowledge base administrators based on criteria such as outdated technology references, superseded processes, or low usage frequency. A review process will be implemented, allowing for verification before removal. Entries deemed obsolete will be archived for a specified period (e.g., 6 months) before permanent deletion.
Migration Planning
A well-defined migration plan is critical for transitioning the knowledge base to a new platform, minimizing downtime and ensuring data integrity.
The target platform for migration is a cloud-based solution (e.g., AWS or Azure) offering enhanced scalability, reliability, and security. Table 2 Artikels the migration timeline, including key milestones and dependencies. A phased rollout strategy will be employed, gradually migrating sections of the knowledge base to the new platform. This minimizes the risk of widespread disruption and allows for continuous monitoring and adjustment during the migration process.
To minimize downtime, a blue-green deployment strategy will be implemented. The new platform will be set up in parallel with the existing system. Once testing is complete, traffic will be switched to the new platform with minimal interruption. Comprehensive testing, including functional and performance tests, will be conducted to validate the migrated knowledge base before full deployment.
Acceptance criteria will include successful data migration, consistent functionality, and performance metrics meeting pre-defined thresholds.
Security Considerations within Scalability and Maintainability
Security is paramount throughout the scaling and maintenance processes. Robust measures must be implemented to protect the knowledge base during these operations.
Access control will be enforced using role-based access control (RBAC), ensuring only authorized personnel can access and modify the knowledge base. Data encryption, both in transit and at rest, will protect sensitive information. Data integrity checks will be implemented to detect and prevent unauthorized modifications. Specific security technologies include encryption using TLS/SSL, intrusion detection systems, and regular security audits.
A disaster recovery plan is crucial to ensure business continuity in case of system failure or data loss. This plan includes regular backups, geographically redundant data storage, and a detailed restoration procedure. Recovery time objectives (RTO) and recovery point objectives (RPO) will be defined and regularly tested to ensure they meet business requirements. For example, an RTO of 4 hours and an RPO of 2 hours might be targeted, indicating a maximum acceptable downtime of 4 hours and a maximum acceptable data loss of 2 hours in case of a disaster.
Training and Onboarding for Knowledge Base Users
Effective training and onboarding are crucial for maximizing the utility of the Incident IQ knowledge base. A well-structured program ensures users quickly become proficient in navigating and utilizing the system’s resources, leading to improved incident resolution times and overall operational efficiency. This program focuses on providing both initial and ongoing support, empowering users to independently access and leverage the knowledge base effectively.
Training Program Design
The training program will employ a blended learning approach, combining self-paced online modules with instructor-led sessions. This approach caters to diverse learning styles and ensures comprehensive knowledge acquisition. The self-paced modules will cover foundational aspects of the knowledge base, allowing users to learn at their own speed. Instructor-led sessions will focus on practical application, problem-solving, and advanced features, facilitating interactive learning and addressing specific user queries.
The program will be modular, allowing for customization based on user roles and experience levels. For example, basic users might receive training focused on searching and retrieving information, while advanced users might receive training on content creation and management.
Key Features and Functionalities Training Checklist
The following checklist Artikels the key features and functionalities that will be covered during the training program. This ensures consistent coverage of essential aspects and minimizes the learning curve for all users.
- Account Creation and Login: Understanding user accounts, login procedures, and password management.
- Navigation and Search: Efficiently navigating the knowledge base interface and utilizing search functionalities ( searches, advanced filters).
- Content Organization and Structure: Understanding the knowledge base’s organizational structure (categories, tags, hierarchies) to locate relevant information.
- Article Viewing and Interaction: Reading and interacting with articles (rating, commenting, feedback).
- Content Contribution (if applicable): Creating and editing articles, adhering to style guides and best practices (relevant only for designated users).
- Reporting and Feedback Mechanisms: Providing feedback on existing content and reporting inaccuracies or missing information.
- Integration with Other Systems: Understanding how the knowledge base integrates with other systems used within the organization (e.g., ticketing systems).
Ongoing Support and Assistance Plan
Continuous support is vital to ensure sustained knowledge base usage and effectiveness. This plan Artikels several mechanisms for providing ongoing assistance to users.
- FAQ Section: A comprehensive frequently asked questions (FAQ) section will be maintained and regularly updated to address common user queries.
- Help Desk Support: A dedicated help desk will provide prompt support for users encountering difficulties or requiring assistance with specific issues.
- Regular Training Refresher Sessions: Periodic refresher sessions will be conducted to reinforce key concepts and address any updates or changes to the knowledge base.
- User Feedback Mechanisms: Regular feedback mechanisms will be implemented to gather user input and identify areas for improvement in the knowledge base and training program itself.
- Knowledge Base Updates Notifications: Users will receive notifications about significant updates to the knowledge base, ensuring they are aware of new content and functionalities.
Troubleshooting Common Issues
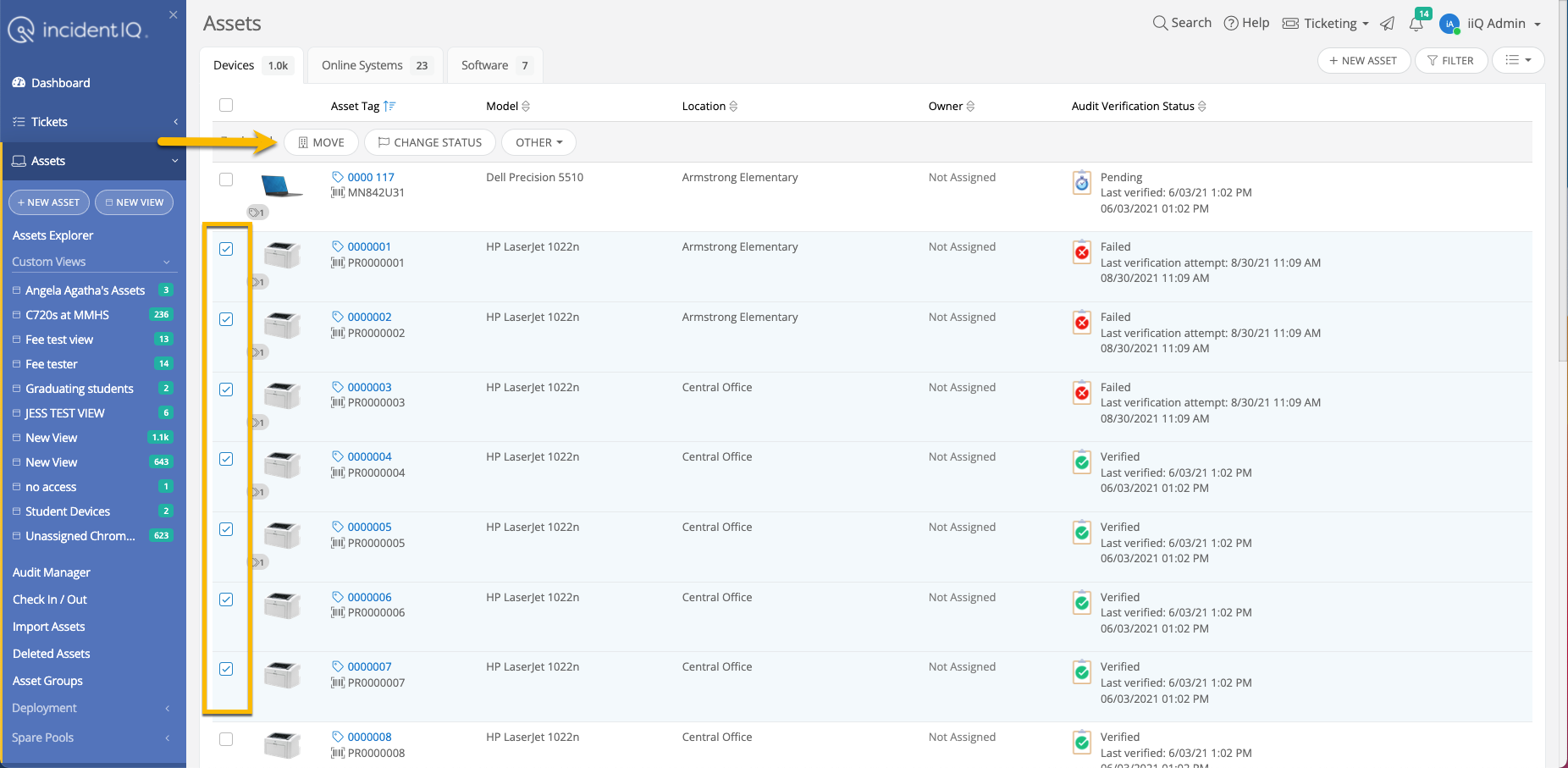
This section details common problems encountered when using the Incident IQ knowledge base, along with solutions and troubleshooting steps. The information is based on user support tickets submitted over the last three months. We aim to provide clear, concise solutions for users with varying levels of technical expertise.
Common User Problems and Solutions
The following list Artikels common issues reported by users, categorized by problem area. Each issue includes detailed troubleshooting steps.
- Inaccurate Search Results: Users frequently report finding irrelevant articles when searching the knowledge base. This is often due to using vague search terms or relying solely on matching.
- Solution: Use more specific s. Instead of “network problem,” try “network connectivity issues VPN.” Utilize advanced search operators (if available) such as Boolean operators (AND, OR, NOT) to refine your search. For example, searching “network issue AND VPN” will only return articles that mention both terms.
Experiment with different phrasing and synonyms for your search terms. If the problem persists, verify that auto-correct isn’t altering your search query.
- Example Error Message: “No results found for your search.” This message indicates that the knowledge base did not find any articles matching your search criteria.
- Solution: Use more specific s. Instead of “network problem,” try “network connectivity issues VPN.” Utilize advanced search operators (if available) such as Boolean operators (AND, OR, NOT) to refine your search. For example, searching “network issue AND VPN” will only return articles that mention both terms.
- Inability to Find Relevant Articles: Users may struggle to locate articles even with precise search terms, indicating potential issues with knowledge base organization or indexing.
- Solution: Review the knowledge base’s category structure and navigation menus. Utilize the filtering options (if available) to narrow down the search results based on categories, tags, or other relevant metadata. If the desired information still remains elusive, submit a feedback report outlining the missing information and desired search terms.
- Example Error Message: (While there isn’t a specific error message, the lack of relevant results is the problem itself.)
- Broken Links: Users may encounter broken links within articles, preventing them from accessing related content.
- Solution: If you encounter a broken link, try copying the URL and pasting it directly into your browser. If the link remains broken, report the issue through the feedback mechanism within the knowledge base. Include the broken link’s URL and the article where it was found.
The support team will investigate and update the link accordingly.
- Example Error Message: “404 Not Found” or a similar error message indicating the page does not exist.
- Solution: If you encounter a broken link, try copying the URL and pasting it directly into your browser. If the link remains broken, report the issue through the feedback mechanism within the knowledge base. Include the broken link’s URL and the article where it was found.
- Outdated Information: Users may find outdated or conflicting information within articles.
- Solution: Check the article’s last updated date. If the information appears outdated, report it via the knowledge base feedback mechanism. Include the article’s URL and specific details about the outdated information. Note that if multiple versions of an article exist, refer to the most recently updated one.
- Example Error Message: There’s no specific error message for outdated information. The issue is identified by the user recognizing inconsistencies or outdated facts within the article content.
Frequently Asked Questions (FAQ)
This section answers common questions regarding the Incident IQ knowledge base.Accessing the Knowledge Base: The knowledge base is accessible through the company intranet at [Intranet URL] and via the mobile app (available on iOS and Android app stores). A screenshot of the intranet login page would show the login form with fields for username and password. A screenshot of the mobile app’s home screen would display the app’s main menu and search bar.Searching the Knowledge Base: To search the knowledge base, type your s into the search bar located at the top of the page.
Use quotation marks to search for exact phrases. For example, searching “network connectivity issues” will only return articles containing that exact phrase. Boolean operators (AND, OR, NOT) can further refine your search.Understanding Article Structure: Articles are organized by category and sub-category. Each article has a clear title, introduction, steps, and a conclusion. Related articles are linked at the end of each article.
A screenshot illustrating a sample article structure would showcase the title, introduction, numbered steps, and related links.Reporting Problems: To report problems or suggest improvements, click on the “Feedback” button located at the bottom of each article or the main page. A feedback form will appear, allowing you to describe the issue and provide relevant details.
Common Issues Summary Table
| Issue | Solution | FAQ Entry Reference | Severity |
|---|---|---|---|
| Inaccurate Search Results | Use more specific s, advanced search operators. | Searching the Knowledge Base | Medium |
| Inability to Find Relevant Articles | Review category structure, use filtering options, submit feedback. | Searching the Knowledge Base, Reporting Problems | High |
| Broken Links | Report the issue via feedback mechanism. | Reporting Problems | High |
| Outdated Information | Report the issue via feedback mechanism. | Reporting Problems | High |
Troubleshooting Slow Loading Times, Incident iq knowledge base
Troubleshooting Slow Loading Times: If the knowledge base is loading slowly, first check your internet connection. If your connection is stable, try clearing your browser’s cache and cookies. If the problem persists, please contact support for assistance.
Recommendations for Improvement
- Improve search algorithm to handle synonyms and misspellings more effectively.
- Implement a more intuitive category and navigation structure.
- Introduce a tagging system to improve article discovery.
- Implement a more robust system for tracking and managing article updates.
- Regularly review and update content to ensure accuracy.
Future Improvements and Enhancements

The Incident IQ knowledge base, while currently functional, possesses significant potential for improvement and expansion. Future enhancements should focus on increasing user engagement, improving search capabilities, and integrating more seamlessly with existing incident management workflows. This will ultimately lead to faster resolution times, reduced incident recurrence, and a more efficient support team.
Several key areas present opportunities for enhancing the knowledge base’s effectiveness and usability. These enhancements will be implemented strategically, prioritizing features with the highest impact on user experience and operational efficiency. A phased approach will allow for iterative development and testing, ensuring the smooth integration of new functionalities.
Enhanced Search Functionality
Implementing advanced search capabilities, such as fuzzy matching and semantic search, will dramatically improve the user experience. Currently, -based searches may miss relevant articles due to slight variations in terminology. Fuzzy matching allows for searches to return results even with minor spelling errors or variations in phrasing, while semantic search considers the meaning and context of search queries, leading to more accurate and relevant results.
For example, a search for “network outage” might also return articles related to “connectivity issues” or “internet downtime” using semantic search. This improved accuracy will reduce search time and frustration for users.
Personalized Knowledge Base Experience
Personalization can significantly improve the user experience by tailoring the content presented to individual users based on their roles, past searches, and incident types they frequently handle. For instance, a system administrator might see articles related to server maintenance more prominently than a help desk agent who primarily deals with user account issues. This can be achieved through user profiling and machine learning algorithms that analyze user behavior to suggest relevant articles proactively.
A successful implementation could mimic popular e-commerce sites’ recommendation systems, offering tailored content based on user interaction history.
Improved Content Contribution and Collaboration
Facilitating easier content contribution and collaboration among subject matter experts (SMEs) is crucial for maintaining an up-to-date and comprehensive knowledge base. Implementing a user-friendly content contribution workflow with version control and approval processes will streamline the process. Features like collaborative editing and commenting tools can further enhance teamwork and knowledge sharing. This would mirror the collaborative features found in platforms like Google Docs or Microsoft SharePoint, enabling multiple users to work on the same article simultaneously while tracking changes.
Integration with External Monitoring Tools
Integrating the knowledge base with existing monitoring tools can provide proactive support. When a monitoring system detects an incident, the system could automatically suggest relevant knowledge base articles to the responding team. This proactive approach can significantly reduce the time required to diagnose and resolve incidents. For example, if a system detects high CPU usage on a specific server, it could automatically display articles related to CPU optimization or troubleshooting.
This integration could be achieved through APIs, allowing for seamless data exchange between systems.
Gamification and Incentives
Introducing elements of gamification, such as points, badges, or leaderboards, can incentivize users to contribute to and engage with the knowledge base. Rewarding users for creating high-quality articles or providing helpful feedback can foster a more active and collaborative community. This approach has been successfully implemented in various online platforms to encourage user participation and engagement. Examples include awarding points for creating well-rated articles or providing insightful feedback on existing content.
Roadmap for Implementation
The implementation of these improvements will follow a phased approach, prioritizing features based on their impact and feasibility. Phase 1 will focus on enhanced search functionality and improved content contribution workflows. Phase 2 will incorporate personalization and integration with external monitoring tools. Phase 3 will introduce gamification and incentives to encourage user engagement. Each phase will involve rigorous testing and user feedback to ensure successful implementation and continuous improvement.
Comparison with Alternative Knowledge Base Solutions
This section compares Incident IQ’s knowledge base functionality with three leading competitors: Zendesk, Freshdesk, and Salesforce Knowledge. The comparison considers strengths, weaknesses, key features, pricing, integration capabilities, and user experience to provide a comprehensive overview for organizations seeking a suitable knowledge base solution for incident management. The analysis aims to highlight the key differentiators and assist in informed decision-making based on specific organizational needs and priorities.
Comparative Analysis of Knowledge Base Solutions
| Solution Name | Strengths | Weaknesses | Key Features |
|---|---|---|---|
| Incident IQ |
|
|
|
| Zendesk |
|
|
|
| Freshdesk |
|
|
|
| Salesforce Knowledge |
|
|
|
Pricing Comparison
| Solution | Pricing Model | Pricing Tiers & Features |
|---|---|---|
| Incident IQ | Tiered, per-user/agent | Contact sales for pricing details.1 |
| Zendesk | Tiered, per-agent | Pricing varies widely based on features and agents.2 |
| Freshdesk | Tiered, per-agent | Offers various plans with different feature sets and agent limits.3 |
| Salesforce Knowledge | Part of Salesforce platform pricing | Pricing bundled with Salesforce subscriptions; varies widely.4 |
Comparative Analysis Summary
The optimal knowledge base solution depends heavily on organizational size, budget, and technical expertise. Incident IQ excels in incident management integration and robust reporting, making it ideal for organizations prioritizing these features. Zendesk offers a user-friendly experience and extensive integrations, suitable for organizations with diverse needs and a preference for ease of use. Freshdesk provides a cost-effective option for smaller businesses, while Salesforce Knowledge offers the most comprehensive functionality but demands a significant investment and technical expertise. Careful consideration of these factors is crucial for selecting the most appropriate solution.
Top FAQs
What are the key benefits of using an Incident IQ knowledge base?
Reduced resolution times, improved user self-service capabilities, enhanced collaboration among IT teams, and a centralized repository for troubleshooting information.
How do I ensure the knowledge base remains up-to-date and relevant?
Implement a regular review and update process with clearly defined roles and responsibilities, utilize automated tagging and indexing, and actively solicit user feedback.
What security measures should be in place for the knowledge base?
Implement robust access controls (RBAC and ACLs), data encryption (both at rest and in transit), regular security audits and vulnerability scanning, and a comprehensive disaster recovery plan.
How can I integrate the Incident IQ knowledge base with other systems?
Leverage APIs to integrate with other incident management tools, ticketing systems, and communication platforms. Consider using webhooks for automated updates.
What metrics should I track to measure the effectiveness of the knowledge base?
Track key performance indicators (KPIs) such as search volume, article views, resolution times, and user satisfaction scores.

