
How to train ai chatbot with custom knowledge base – How to train AI chatbots with a custom knowledge base is a fascinating journey into the heart of artificial intelligence. Imagine crafting a chatbot that speaks with the unique voice of your brand, effortlessly answering customer queries from a meticulously curated database of FAQs and product manuals. This isn’t science fiction; it’s a powerful technique that can transform your customer service, enhance product support, and even revolutionize internal knowledge sharing.
This guide will equip you with the knowledge and tools to bring this vision to life, step by step.
We’ll navigate the entire process, from meticulously preparing your data – transforming messy PDFs and unstructured text into a format AI can understand – to selecting and training the perfect AI model for your specific needs. We’ll explore various data preprocessing techniques, feature engineering strategies, and model optimization methods to ensure your chatbot delivers accurate, relevant, and engaging responses.
We’ll even touch upon crucial ethical considerations and deployment strategies, empowering you to build a responsible and effective AI solution.
Data Preparation and Preprocessing
Preparing a robust knowledge base is paramount for training a high-performing AI chatbot. This involves meticulous cleaning, structuring, and preprocessing of your data, specifically your customer service FAQs and product manuals. The goal is to transform raw, often inconsistent information into a clean, structured format suitable for machine learning algorithms.
Knowledge Base Cleaning and Preparation
This stage focuses on cleaning and preparing the FAQs and product manuals (in PDF format) for AI chatbot training. The process involves several crucial steps. First, PDF files need to be converted into a machine-readable format like text. Inconsistencies in formatting (e.g., varying font sizes, inconsistent use of bolding or italics) are addressed through normalization techniques. We standardize formatting to ensure uniformity.
For instance, all headings could be converted to a consistent font size and style. Next, we tackle terminology inconsistencies. Synonyms and different phrasing referring to the same product or service are identified and mapped to a single, consistent term. For example, “customer support” might be used interchangeably with “help desk” or “technical assistance,” and these are all mapped to a single standardized term.
Finally, data entry errors (typos, grammatical errors, and missing information) are corrected using automated spell checkers and manual review.
Handling Noisy/Incomplete Data
Noisy or incomplete data is a common challenge in knowledge base creation. Missing values in FAQ answers and inconsistent product specifications in manuals are addressed using a combination of techniques. We establish a threshold for acceptable missing data—typically, less than 5% missing data per field is acceptable. Beyond this, imputation or removal becomes necessary. For missing FAQ answers, we may use the mode (most frequent answer) if there are similar questions with complete answers.
For inconsistent product specifications, we might use a combination of methods: for numerical data, median imputation can be more robust to outliers than mean imputation. For categorical data, mode imputation is often used. K-NN imputation, which uses the values of the nearest neighbors, could be considered, but it requires careful selection of the appropriate number of neighbors.
Removing entries with extensive missing data is also a possibility, but should be used cautiously as it may lead to a significant reduction in the dataset.
Unstructured Data Conversion
Converting unstructured PDFs and text files into a structured format is crucial. We use Python libraries like PyPDF2 and Tika to extract text from PDFs, handling various encoding types and potential errors. PyPDF2 allows direct text extraction, while Tika provides a more robust solution for complex PDFs, including those with embedded images and tables. The target structured format is JSON, chosen for its flexibility in representing complex data structures.
The conversion process involves extracting text, cleaning it, and then structuring it into JSON objects. Each FAQ or product specification section becomes a JSON object with key-value pairs representing question, answer, product name, specification, etc.“`pythonimport PyPDF2import jsondef convert_pdf_to_json(pdf_path, output_path): with open(pdf_path, ‘rb’) as pdf_file: reader = PyPDF2.PdfReader(pdf_file) num_pages = len(reader.pages) text = “” for page_num in range(num_pages): page = reader.pages[page_num] text += page.extract_text() #Further processing of the extracted text to create JSON structure # …
(code to structure text into JSON objects) … with open(output_path, ‘w’) as json_file: json.dump(json_data, json_file, indent=4)“`
Data Preprocessing Technique Comparison
Various preprocessing techniques enhance the quality of the data. The choice of techniques depends on the specific characteristics of the knowledge base.
| Technique | Description | Pros | Cons | Python Library |
|---|---|---|---|---|
| Tokenization | Breaking text into individual words or phrases | Creates manageable units for processing | Can lose contextual information | NLTK, spaCy |
| Stemming | Reducing words to their root form | Reduces vocabulary size | Can produce non-dictionary words | NLTK, spaCy |
| Lemmatization | Reducing words to their dictionary form | Produces meaningful words | Computationally more expensive than stemming | NLTK, spaCy |
| Stop Word Removal | Removing common words (e.g., “the,” “a,” “is”) | Reduces noise and improves efficiency | Can lose some contextual information | NLTK, spaCy |
| Named Entity Recognition (NER) | Identifying and classifying named entities (e.g., people, organizations, locations) | Extracts key information | Can be complex and resource-intensive | spaCy, Stanford NER |
Data Validation
Validating the preprocessed data is crucial to ensure its quality. This involves checking for data type consistency (e.g., ensuring that numerical data is correctly formatted), identifying and handling any remaining missing values, and detecting and removing duplicate entries. Metrics like data completeness (percentage of non-missing values), consistency (percentage of values matching expected patterns), and uniqueness (percentage of unique entries) are used to assess data quality.
Data profiling tools can help automate this process.
Knowledge Base Representation
Choosing the right knowledge representation method is crucial for building an effective AI chatbot. The way you structure your data directly impacts the chatbot’s ability to understand, reason, and respond appropriately. Different methods offer varying levels of expressiveness, scalability, and ease of implementation. The ideal choice depends heavily on the complexity of your knowledge base and the desired capabilities of your chatbot.
Knowledge Representation Methods
Several methods exist for representing knowledge suitable for AI chatbots. Each offers unique advantages and disadvantages. The most common approaches include knowledge graphs, ontologies, and vector embeddings.
Knowledge Graphs, How to train ai chatbot with custom knowledge base
Knowledge graphs represent knowledge as a network of interconnected entities and their relationships. Entities are represented as nodes, and relationships are represented as edges connecting these nodes. For example, a knowledge graph representing information about books might include nodes for “author,” “book title,” “publication year,” and “genre,” with edges connecting these nodes to represent the relationships between them.
This structure allows for complex reasoning and inference capabilities.
Ontologies
Ontologies are formal representations of knowledge that define concepts, relationships, and properties within a specific domain. They provide a more structured and rigorous approach than knowledge graphs, explicitly defining the meaning and relationships between concepts. Ontologies are often used in scenarios requiring precise semantic understanding and knowledge sharing, such as in scientific research or complex business domains. They typically use formal languages like OWL (Web Ontology Language) for representation.
Vector Embeddings
Vector embeddings represent knowledge as numerical vectors in a high-dimensional space. Each vector captures the semantic meaning of a piece of information, such as a word, phrase, or even an entire document. The similarity between two pieces of information can be measured by calculating the distance between their corresponding vectors. This approach is particularly useful for tasks involving natural language processing, such as question answering and text generation.
Word2Vec and BERT are examples of popular techniques for generating vector embeddings.
Comparison of Knowledge Representation Methods
| Method | Advantages | Disadvantages |
|---|---|---|
| Knowledge Graphs | Intuitive, supports complex reasoning, scalable | Can be challenging to create and maintain, requires significant upfront effort |
| Ontologies | Formal, precise, facilitates knowledge sharing | Steeper learning curve, complex to design and implement, less scalable than knowledge graphs |
| Vector Embeddings | Efficient, suitable for NLP tasks, readily available pre-trained models | Difficult to interpret, may not capture all nuances of meaning, less suitable for complex reasoning |
Creating a Knowledge Graph from a Custom Knowledge Base
The process of creating a knowledge graph involves several steps:
- Identify Entities and Relationships: Determine the key entities and relationships within your knowledge base. For example, in a knowledge base about movies, entities might include “movie,” “actor,” “director,” and “genre,” while relationships might include “directed by,” “starred in,” and “belongs to.”
- Define a Schema: Establish a schema that defines the types of entities and relationships, along with their properties. This schema serves as a blueprint for your knowledge graph.
- Data Extraction and Transformation: Extract relevant information from your knowledge base and transform it into a format suitable for the knowledge graph. This might involve parsing text, cleaning data, and standardizing terminology.
- Graph Construction: Populate the knowledge graph by creating nodes for entities and edges for relationships, according to the defined schema. Tools like Neo4j or Amazon Neptune can assist in this process.
Knowledge Graph Schema Example: Movie Domain
Let’s design a schema for representing knowledge about movies using a knowledge graph. We’ll use a simple schema for illustrative purposes.
| Entity Type | Properties |
|---|---|
| Movie | title, releaseYear, genre, director, actors |
| Actor | name, birthYear |
| Director | name, birthYear |
| Genre | name |
Relationships would include:
directedBy(Movie, Director)starredIn(Movie, Actor)belongs_to(Movie, Genre)
This schema allows for representing movies and their associated information in a structured and interconnected manner. For instance, the movie “The Matrix” would be represented as a node with properties such as title (“The Matrix”), releaseYear (1999), and genre (“Science Fiction”). It would be connected to nodes representing its director (Lana Wachowski and Lilly Wachowski) and actors (Keanu Reeves, Laurence Fishburne, etc.) via the appropriate relationship edges.
Choosing the Right AI Model

Selecting the optimal AI model for training your chatbot with a custom knowledge base is crucial for achieving desired performance. The choice hinges on several factors, including the size and structure of your knowledge base, the complexity of the expected interactions, and the desired level of accuracy and efficiency. A careful consideration of these factors will significantly impact the overall success of your chatbot.
Comparison of AI Models for Chatbot Training
Several AI model architectures are suitable for chatbot training, each with its strengths and weaknesses. Transformers, Recurrent Neural Networks (RNNs), and variations thereof are commonly employed. Transformers, exemplified by models like BERT and GPT, excel in handling long-range dependencies within text, making them ideal for understanding context across extended conversations. RNNs, such as LSTMs and GRUs, are effective at processing sequential data, capturing the temporal order of information within a conversation.
However, RNNs can struggle with very long sequences due to vanishing or exploding gradients. The choice between these architectures often depends on the specific needs of the application. For instance, a chatbot designed for concise, factual responses might benefit from a simpler RNN architecture, while a chatbot requiring nuanced understanding of context over extended dialogue would be better served by a transformer model.
Training an AI chatbot with a custom knowledge base requires meticulous data preparation. A crucial step involves structuring this information effectively; understanding how to organize a knowledge base, as detailed in this helpful guide how to organize a knowledge base , directly impacts the chatbot’s accuracy and efficiency. Proper organization ensures the AI can quickly access and process relevant information, leading to more effective and informative responses.
Factors to Consider When Selecting an AI Model
The selection process should prioritize several key factors. The size of the knowledge base directly impacts computational requirements. A large knowledge base might necessitate a more efficient model architecture to avoid excessively long training times. The complexity of the expected interactions, whether involving simple question-answering or intricate dialogue management, influences the model’s complexity. The desired accuracy and efficiency are also paramount.
A high-accuracy model might require more computational resources and training time, while a less demanding model might offer a faster solution but at the cost of accuracy. Finally, the type of knowledge base data – structured, semi-structured, or unstructured – dictates the suitability of different model architectures.
Strengths and Weaknesses of Different Model Architectures
Transformers demonstrate exceptional performance in understanding context and generating coherent responses, particularly in large language models. However, they can be computationally expensive to train and deploy, requiring significant resources. RNNs, while less computationally demanding than transformers, may struggle with long conversations due to their sequential nature and limitations in capturing long-range dependencies. Furthermore, the type of knowledge base data significantly impacts model choice.
Structured data, such as knowledge graphs, might benefit from knowledge graph embedding models, which explicitly represent relationships between entities. Unstructured data, like text documents, is better handled by transformer or RNN-based models capable of processing and understanding natural language.
Selecting Appropriate Model Hyperparameters
Hyperparameter tuning is crucial for optimizing model performance. Factors such as the learning rate, batch size, and number of layers directly influence training speed and accuracy. For instance, a larger batch size can speed up training but might require more memory. The learning rate determines the step size during gradient descent, with smaller learning rates leading to more stable but slower convergence.
The number of layers in a neural network affects its capacity to learn complex patterns, with deeper networks capable of learning more intricate relationships but also being more prone to overfitting. The optimal hyperparameters are typically determined through experimentation and validation using a held-out portion of the knowledge base data. Techniques like grid search or Bayesian optimization can assist in this process.
For example, experimenting with different learning rates (e.g., 0.001, 0.01, 0.1) and batch sizes (e.g., 32, 64, 128) on a subset of the knowledge base can help determine the best configuration for the specific dataset and model architecture.
Training the AI Chatbot
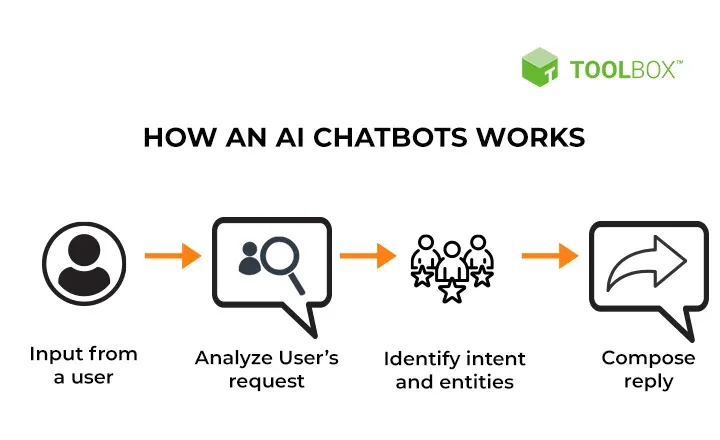
Training your custom AI chatbot involves feeding your prepared knowledge base to the chosen model, allowing it to learn the relationships between the data and generate appropriate responses. This process isn’t a simple one-time action; it often requires iterative refinement and adjustment based on the model’s performance. Think of it like teaching a child – you provide examples, correct mistakes, and gradually build their understanding.The core of the training process lies in the interaction between your data and the model’s algorithms.
The model uses sophisticated techniques, often involving neural networks, to identify patterns, relationships, and contextual nuances within your knowledge base. This enables it to generate coherent and relevant responses to user queries. The complexity of this process depends heavily on the chosen model and the size and complexity of your knowledge base.
Model Training Process
The training process typically involves several steps. First, the prepared data—which might include text, code, or other structured information—is loaded into the model. This loading process can be computationally intensive, especially for large datasets. Next, the model begins to learn from this data, adjusting its internal parameters to minimize errors in its predictions. This iterative process continues until the model reaches a satisfactory level of performance, or until a pre-defined stopping criterion is met.
The process often involves sophisticated optimization algorithms to guide the model towards the best possible performance. For instance, a common technique is backpropagation, where the model adjusts its parameters based on the difference between its predicted output and the actual desired output.
Evaluating Chatbot Performance
Evaluating a trained chatbot is crucial to ensure its accuracy and effectiveness. This involves several metrics, including precision, recall, F1-score, and BLEU score (for evaluating the fluency and similarity of generated text to human-generated text). A high precision indicates that the chatbot’s responses are mostly correct when it claims to have an answer, while high recall indicates that it correctly identifies a large proportion of relevant information.
The F1-score provides a balance between precision and recall. BLEU score, on the other hand, focuses on the quality of the generated text itself. Beyond these metrics, human evaluation is also critical. Human evaluators assess the chatbot’s responses for coherence, relevance, and overall helpfulness. This qualitative assessment provides valuable insights that purely quantitative metrics may miss.
For example, a chatbot might achieve high precision and recall but still produce responses that are grammatically incorrect or nonsensical.
Step-by-Step Training Guide
A typical training process unfolds as follows:
- Data Loading: The pre-processed knowledge base is loaded into the chosen model’s framework. This might involve converting the data into a suitable format, such as a sequence of tokens or embeddings.
- Model Initialization: The chosen AI model (e.g., a transformer-based model like BERT or a large language model like GPT-3) is initialized with its parameters set to initial values.
- Training Loop: The model iteratively processes batches of data, generating predictions, and calculating the loss (a measure of error) between the predictions and the actual values. Optimization algorithms (like Adam or SGD) adjust the model’s parameters to minimize the loss.
- Evaluation: After each epoch (a complete pass through the training data), or at regular intervals, the model’s performance is evaluated on a separate validation dataset. This helps to monitor progress and prevent overfitting (where the model performs well on the training data but poorly on unseen data).
- Hyperparameter Tuning: Based on the evaluation results, hyperparameters (e.g., learning rate, batch size, number of epochs) might be adjusted to optimize the model’s performance. This often involves experimentation and iterative refinement.
- Final Evaluation: Once the model achieves satisfactory performance on the validation set, it is finally evaluated on a held-out test dataset, which was not used during training or validation. This provides an unbiased estimate of the model’s generalization capability.
Training Process Flowchart
Imagine a flowchart. It begins with a “Start” node. The next box represents “Data Loading and Preprocessing.” This leads to a decision point: “Is data ready?”. If yes, it proceeds to “Model Selection and Initialization”. Next is a loop representing “Training Iteration”: “Forward Pass (prediction)”, “Loss Calculation”, “Backpropagation (parameter update)”.
This loop continues until a stopping criterion is met (e.g., a maximum number of epochs or satisfactory performance). Then, it goes to “Model Evaluation”. This leads to a decision point: “Is performance satisfactory?”. If yes, it moves to “Deployment”. If no, it loops back to “Hyperparameter Tuning” and then back to the “Training Iteration” loop.
Finally, there’s an “End” node.
Fine-tuning and Optimization
Fine-tuning and optimization are crucial steps in building a high-performing AI chatbot. These processes refine the model’s capabilities, enhancing its accuracy and efficiency on specific tasks and datasets. This section delves into various techniques for fine-tuning and optimization, covering different model architectures and datasets.
Fine-tuning Techniques for Specific Knowledge Bases
Fine-tuning a pre-trained model, such as BERT, on a specific knowledge base significantly improves its performance on tasks relevant to that knowledge domain. This process involves adapting the pre-trained model’s weights to the nuances of the target dataset, resulting in a more accurate and contextually aware chatbot.Let’s consider a BERT-based model fine-tuned for a knowledge base of 10,000 medical journal abstracts.
The goal is to enhance the accuracy of question answering related to diagnosis and treatment. Data preprocessing is vital. This includes cleaning the abstracts (removing irrelevant characters, handling inconsistencies), tokenizing the text into individual words or sub-word units using a WordPiece tokenizer (common in BERT), and creating input sequences suitable for the BERT architecture. These sequences typically consist of question-answer pairs.Hyperparameter tuning is essential for optimal performance.
This involves experimenting with different values for learning rate (e.g., 2e-5, 3e-5, 5e-5), batch size (e.g., 16, 32, 64), and the number of epochs (e.g., 3, 5, 10). The optimal values depend on the specific dataset and hardware resources. We can use techniques like grid search or Bayesian optimization to efficiently explore the hyperparameter space.Two main fine-tuning strategies exist: feature extraction and full fine-tuning.
Feature extraction freezes the weights of the pre-trained BERT layers and only trains a small task-specific layer on top. This is faster but less effective. Full fine-tuning allows all BERT layers to be updated during training, leading to potentially better performance but requiring more computational resources and potentially increased risk of overfitting. We’d likely choose full fine-tuning for this medical dataset to capture the nuanced relationships between medical concepts.
Careful monitoring of the validation loss is key to avoid overfitting.
Optimizing the Training Process for Efficiency and Accuracy
Training large language models (LLMs) on massive datasets, such as 1 million customer service interactions, presents significant computational challenges. Optimization techniques are crucial for minimizing training time without sacrificing accuracy.Several strategies can improve training efficiency. Gradient accumulation simulates larger batch sizes by accumulating gradients over multiple smaller batches before updating the model’s weights. This reduces memory usage, allowing training with larger effective batch sizes.
Mixed precision training uses both FP16 (half-precision) and FP32 (single-precision) floating-point numbers, reducing memory footprint and speeding up computation. Model parallelism distributes the model across multiple GPUs, enabling training on larger models and datasets that wouldn’t fit on a single GPU.The following table summarizes the comparison of different optimization techniques, assuming a baseline training setup on a single GPU with no optimization strategies.
Note that the actual values would depend heavily on the specific LLM, dataset, and hardware.
| Optimization Technique | Training Time (hours) | Accuracy (%) | Resource Usage (GPU Memory) |
|---|---|---|---|
| Baseline (No Optimization) | 100 | 85 | 24GB |
| Gradient Accumulation | 80 | 86 | 12GB |
| Mixed Precision Training | 60 | 85.5 | 12GB |
| Model Parallelism (4 GPUs) | 25 | 87 | 6GB per GPU |
Strategies for Handling Overfitting and Underfitting
Overfitting occurs when a model learns the training data too well, performing poorly on unseen data. Underfitting occurs when the model is too simple to capture the underlying patterns in the data. Both are detrimental to a model’s generalization ability.When training a recurrent neural network (RNN) on a time series dataset of stock prices, overfitting can be addressed using techniques like dropout (randomly ignoring neurons during training), L1 and L2 regularization (adding penalties to the loss function based on the magnitude of weights), early stopping (monitoring the validation loss and stopping training when it starts to increase), and data augmentation (creating synthetic data points by adding noise or applying transformations to existing data).“`python# Example of dropout in PyTorchmodel = nn.RNN(…)model = nn.Dropout(0.5)(model) # 50% dropout rate# Example of L2 regularization in TensorFlow/Kerasmodel.compile(optimizer=tf.keras.optimizers.Adam(…, weight_decay=0.01)) # L2 regularization with weight decay“`Underfitting can be diagnosed by observing consistently high training and validation losses.
Solutions include increasing model complexity (adding more layers or neurons), using a different model architecture (e.g., LSTM instead of a simple RNN), or using more relevant features. Graphs showing training and validation loss curves would visually illustrate the impact of these techniques, revealing whether overfitting or underfitting is present. A typical graph would show decreasing training and validation loss during initial epochs, with validation loss eventually plateauing or rising if overfitting occurs.
Optimization Algorithms in Chatbot Training
Different optimization algorithms exhibit varying performance characteristics when training dialogue generation models. Comparing AdamW, SGD with momentum, and RMSprop on a Transformer-based chatbot trained on 50,000 conversational turns provides insights into their relative strengths and weaknesses.We’d evaluate the performance using metrics like perplexity (lower is better, indicating better prediction of next words), BLEU score (measures the similarity between generated text and reference text), and ROUGE score (evaluates the overlap of generated and reference text).
AdamW generally outperforms SGD and RMSprop in terms of both convergence speed and final performance metrics for this specific chatbot training task. However, careful hyperparameter tuning is crucial for optimal results with all algorithms. Further investigation is needed to determine the optimal algorithm for different dataset sizes and model architectures.
Evaluation Metrics
Evaluating the performance of an AI chatbot requires a multifaceted approach, going beyond simple accuracy rates. A robust evaluation considers various aspects of the chatbot’s capabilities, encompassing its ability to understand and respond appropriately, the quality of its generated text, and its overall user experience. This section delves into the key metrics and strategies for a comprehensive evaluation.
Metric Descriptions
Several metrics provide different perspectives on chatbot performance. Understanding their strengths and weaknesses is crucial for a balanced assessment.
- Accuracy: Represents the percentage of correct responses. It’s calculated as (True Positives + True Negatives) / Total Responses. Accuracy is straightforward but can be misleading if the dataset is imbalanced. For example, a chatbot consistently predicting the majority class will achieve high accuracy even if it fails to identify minority classes. Requires true positives (correctly identified positive instances), true negatives (correctly identified negative instances), false positives (incorrectly identified positive instances), and false negatives (incorrectly identified negative instances).
- Precision: Measures the proportion of correctly identified positive instances out of all instances identified as positive. Formula: True Positives / (True Positives + False Positives). High precision means few false positives. Requires true positives and false positives.
- Recall (Sensitivity): Measures the proportion of correctly identified positive instances out of all actual positive instances. Formula: True Positives / (True Positives + False Negatives). High recall means few false negatives. Requires true positives and false negatives.
- F1-score: The harmonic mean of precision and recall, providing a balanced measure. Formula: 2
– (Precision
– Recall) / (Precision + Recall). A high F1-score indicates good balance between precision and recall. Requires true positives, false positives, and false negatives. - BLEU (Bilingual Evaluation Understudy) score: Measures the similarity between machine-generated text and reference translations. It calculates n-gram precision, typically using n=1 to 4. A higher BLEU score indicates better translation quality. Requires the generated text and one or more reference texts.
- ROUGE (Recall-Oriented Understudy for Gisting Evaluation) score: A suite of metrics measuring the overlap between the generated text and reference summaries. Different ROUGE variants (ROUGE-N, ROUGE-L, ROUGE-S) consider different aspects of text similarity. Higher ROUGE scores indicate better summarization quality. Requires the generated text and one or more reference texts.
- METEOR (Metric for Evaluation of Translation with Explicit ORdering): Similar to BLEU, but considers synonyms and stemming, providing a more nuanced evaluation. It uses unigram precision and recall, incorporating stemming and synonymy. Higher METEOR scores indicate better translation quality. Requires the generated text and one or more reference texts.
- Perplexity: Measures how well a probability model predicts a sample. Lower perplexity indicates better model performance, meaning the model is more confident in its predictions. It’s calculated as exp(-(log probability of the test set)/number of words). Requires the probability model and the test set.
- Human Evaluation: Involves human judges assessing aspects like fluency (grammatical correctness and naturalness), coherence (logical flow and consistency), and engagement (how interesting and informative the response is). This provides a subjective but valuable perspective on overall quality. Requires human annotators and a set of chatbot responses.
Metric Comparison
The following table compares the discussed metrics:
| Metric Name | Formula | Interpretation | Strengths | Weaknesses | Applicability |
|---|---|---|---|---|---|
| Accuracy | (TP + TN) / Total | Percentage of correct responses | Simple, easy to understand | Can be misleading with imbalanced data | All chatbot types |
| Precision | TP / (TP + FP) | Proportion of true positives among predicted positives | Focuses on minimizing false positives | Ignores false negatives | Task-oriented, information retrieval |
| Recall | TP / (TP + FN) | Proportion of true positives among actual positives | Focuses on minimizing false negatives | Ignores false positives | Task-oriented, information retrieval |
| F1-score | 2
| Harmonic mean of precision and recall | Balances precision and recall | Can be sensitive to extreme values | All chatbot types |
| BLEU | N-gram precision | Measures similarity to reference texts | Widely used, automated | Doesn’t capture meaning well | Translation, summarization |
| ROUGE | Overlap with reference summaries | Measures recall of reference summaries | Various variants capture different aspects | Relies on reference summaries | Summarization |
| METEOR | Unigram precision and recall with synonymy and stemming | More nuanced similarity measure than BLEU | Considers synonyms and stemming | Computationally more expensive | Translation |
| Perplexity | exp(-(log probability)/N) | Measures model confidence | Indicates model uncertainty | Not directly interpretable in terms of user experience | All chatbot types |
| Human Evaluation | Subjective ratings | Assesses fluency, coherence, and engagement | Captures user experience | Subjective, expensive, time-consuming | All chatbot types |
Multiple Metrics Justification
Relying on a single metric provides an incomplete picture. For instance, a chatbot might achieve high accuracy on a specific task but generate grammatically incorrect or incoherent responses. High accuracy without fluency is ultimately unsatisfactory. Therefore, a balanced evaluation requires multiple metrics. Using at least F1-score (for task accuracy), BLEU score (for response quality), and human evaluation (for overall user experience) provides a more comprehensive assessment.
Evaluation Plan Design
This plan evaluates a chatbot designed for providing customer support for a fictional online retailer, “E-Commerce Emporium.”
- Target Metrics: F1-score (to measure the accuracy of answering customer queries correctly), BLEU score (to assess the fluency and grammatical correctness of the chatbot’s responses), and Human Evaluation (to evaluate the overall user experience, including helpfulness, clarity, and politeness). The F1-score is crucial for accuracy in resolving customer issues. BLEU assesses response quality, ensuring grammatical correctness and fluency. Human evaluation captures the subjective aspects of the user experience, ensuring the chatbot is helpful and pleasant to interact with.
- Data Collection Method: For F1-score and BLEU score, we’ll collect a dataset of customer queries and their corresponding correct answers (reference responses). For human evaluation, we’ll use a Likert scale (1-5) to rate responses on helpfulness, clarity, and politeness. Annotators will be given specific guidelines for rating. A sample data collection form includes fields for the customer query, the chatbot response, the correct answer, and the Likert scale ratings for each aspect of the user experience.
- Baseline Performance: We set a baseline F1-score of 0.7, a BLEU score of 0.6, and an average human rating of 3.5 (on a 1-5 scale). These are realistic baselines considering the complexity of customer support interactions.
- Statistical Significance Testing: We’ll use paired t-tests to compare the performance of the chatbot before and after improvements, with a significance level of p < 0.05.
- Data Analysis Plan: Data will be analyzed using descriptive statistics (means, standard deviations) and t-tests. Potential biases in human evaluations will be mitigated by using multiple annotators and inter-annotator agreement analysis.
Bias Detection and Mitigation
Potential biases can arise from skewed training data (e.g., overrepresentation of certain demographics) or from biased human evaluation. To mitigate these, we’ll ensure diverse representation in our training data and employ multiple annotators from diverse backgrounds for human evaluation. Blind evaluation (annotators unaware of the chatbot’s training data) will further reduce bias. We will also analyze results for potential demographic biases in the evaluation metrics.
Ethical Considerations
Transparency in the evaluation process is paramount. Clearly defining the metrics used, the data collection methods, and the limitations of the evaluation are crucial for responsible AI development. Misinterpreting or misrepresenting evaluation results can lead to biased or unfair systems. We must prioritize ethical considerations throughout the entire evaluation process.
Deployment and Integration: How To Train Ai Chatbot With Custom Knowledge Base
Deploying your meticulously trained AI chatbot marks a crucial transition from the theoretical to the practical. Success hinges on selecting the right deployment strategy and seamlessly integrating the chatbot into your target environment. This process requires careful consideration of scalability, reliability, and user experience.Deployment methods vary significantly, each with its own set of advantages and disadvantages. The optimal choice depends on factors such as budget, technical expertise, and the scale of your application.
Cloud-Based Deployment Platforms
Cloud platforms like AWS, Google Cloud, and Azure offer scalable and cost-effective solutions for deploying AI chatbots. These platforms provide managed services that handle infrastructure management, allowing developers to focus on chatbot functionality. For example, AWS offers services like Amazon Lex and Amazon Connect, simplifying the deployment and management of conversational AI applications. These platforms often include features for automatic scaling, ensuring the chatbot can handle fluctuating user loads efficiently.
The cost is generally subscription-based, scaling with usage.
On-Premise Deployment
On-premise deployment involves hosting the chatbot on your own servers within your organization’s infrastructure. This offers greater control over data security and compliance, but necessitates managing the underlying infrastructure, including server maintenance, updates, and security. This approach is often preferred when dealing with sensitive data subject to strict regulatory requirements. The initial investment can be higher due to hardware and software costs, but ongoing operational expenses might be lower depending on existing infrastructure.
Chatbot Integration into Existing Applications
Integrating a chatbot into an existing application requires a well-defined API strategy. The chatbot’s responses should be seamlessly integrated into the application’s user interface, ensuring a cohesive user experience. Common integration methods include REST APIs, allowing the application to send user queries to the chatbot and receive responses. The application’s design should account for potential latency in receiving chatbot responses.
A well-designed integration will provide a smooth transition between the application and the chatbot interaction, making the experience feel natural and intuitive. For example, a customer service application could integrate the chatbot to handle initial inquiries, routing complex issues to human agents only when necessary.
Ensuring Scalability and Reliability
Scalability and reliability are paramount for production chatbot deployments. Load balancing across multiple servers is crucial to handle peak demand. Robust error handling and monitoring mechanisms are essential to ensure the chatbot remains available and responsive even during unexpected issues. Regular backups and disaster recovery planning are vital to minimize downtime. Implementing a system for collecting user feedback and analyzing chatbot performance helps identify areas for improvement and ensures continuous optimization.
Performance monitoring tools should be used to track key metrics such as response time, error rates, and user satisfaction.
Deployment and Monitoring Checklist
Before deploying a chatbot to a production environment, a comprehensive checklist is vital. This checklist should cover various aspects of the deployment process, from infrastructure setup to performance monitoring.
- Infrastructure Setup: Verify server capacity, network configuration, and security measures.
- API Integration Testing: Thoroughly test the chatbot’s integration with the target application.
- Load Testing: Simulate peak user loads to assess the chatbot’s scalability.
- Security Auditing: Conduct a security audit to identify and mitigate potential vulnerabilities.
- Monitoring Setup: Implement monitoring tools to track key performance indicators (KPIs).
- Alerting System: Configure alerts for critical errors and performance issues.
- Rollback Plan: Establish a rollback plan in case of deployment failures.
- Documentation: Maintain comprehensive documentation of the deployment process.
Handling Ambiguity and Uncertainty
Building a robust AI chatbot requires addressing the inherent ambiguity and uncertainty present in both user queries and the knowledge base itself. A truly effective chatbot needs to navigate these challenges gracefully, providing helpful responses even when faced with incomplete or contradictory information. This section explores techniques for managing ambiguity and uncertainty, ensuring your chatbot remains informative and reliable.
Ambiguity in natural language is a significant hurdle. Users may phrase their queries in multiple ways, leading to multiple interpretations. Similarly, the knowledge base might contain overlapping or conflicting information, creating uncertainty for the AI. Addressing these challenges requires a multi-pronged approach, encompassing sophisticated natural language processing (NLP) techniques, robust knowledge representation strategies, and carefully designed response mechanisms.
Techniques for Handling Ambiguous Queries
Effective handling of ambiguous queries hinges on leveraging advanced NLP techniques. These techniques aim to disambiguate the user’s intent by analyzing the context, identifying s, and employing semantic analysis. For example, a query like “Apple’s new product” could refer to a new Apple phone, a new software release, or a new type of food. The chatbot can use contextual clues from the conversation or the user’s profile to infer the correct interpretation.
Furthermore, incorporating techniques like named entity recognition (NER) can help identify key entities in the query and resolve ambiguities based on the identified entities. The chatbot can then refine its search within the knowledge base, focusing on information relevant to the specific entity identified.
Methods for Managing Incomplete or Contradictory Information
Incomplete or contradictory information within the knowledge base can severely impact the chatbot’s performance. One approach is to employ a probabilistic knowledge representation, where information is associated with confidence levels. This allows the chatbot to weigh different pieces of information and prioritize those with higher confidence scores. Furthermore, the chatbot can be designed to identify and flag contradictory information, potentially prompting the user for clarification or indicating the presence of conflicting data in its response.
For instance, if the knowledge base contains conflicting information about a historical event, the chatbot can present both perspectives, highlighting the disagreement and acknowledging the uncertainty.
Strategies for Managing Uncertainty in Chatbot Responses
Managing uncertainty in responses is crucial for maintaining user trust and satisfaction. Instead of providing definitive answers when faced with uncertain information, the chatbot can employ hedging strategies. This involves using language that acknowledges the uncertainty, such as “to the best of my knowledge,” or “based on the available information.” The chatbot can also provide a range of possible answers or suggest additional resources for the user to explore.
For example, if asked about the exact population of a city, the chatbot might respond with a range and a reference to an official source for the most up-to-date figures.
Handling Out-of-Scope Queries
A robust chatbot should gracefully handle queries that fall outside the scope of its knowledge base. A simple “I’m sorry, I don’t have information on that topic” is insufficient. Instead, the chatbot can attempt to identify related topics or suggest external resources where the user might find the answer. This could involve searching the web for relevant information or directing the user to a specific website or help center.
The key is to provide a helpful and informative response, even when the chatbot cannot directly answer the query. This might involve suggesting similar questions it
can* answer, or recommending alternative search terms.
Continuous Learning and Improvement
A truly intelligent chatbot isn’t static; it learns and adapts. Continuous improvement is paramount, ensuring the chatbot remains accurate, efficient, and user-friendly over time. This involves establishing robust monitoring systems, implementing targeted retraining strategies, and adapting to evolving knowledge bases and user behaviors. The goal is to create a self-improving system that continuously enhances its performance and user experience.
Automated Performance Monitoring and Feedback Loops
Effective monitoring is the cornerstone of continuous improvement. A well-designed system tracks key performance indicators (KPIs) to identify areas needing attention. This allows for proactive intervention, preventing minor issues from escalating into significant problems.
- Key Performance Indicators (KPIs) Tracking: A comprehensive system tracks user satisfaction scores (gathered through post-interaction surveys using a 1-5 star rating scale), task completion rates (percentage of user queries successfully resolved), and average handling time (average time taken to respond to a query in seconds). These metrics provide a holistic view of chatbot performance.
- Identifying Areas for Improvement: The system analyzes the collected KPIs. If the average satisfaction score drops below 4.0, the task completion rate falls below 90%, or the average handling time exceeds 60 seconds, it triggers an alert, indicating the need for intervention. Further analysis pinpoints the specific conversational flows or knowledge areas causing the decline.
- Incorporating User Feedback: User feedback, both positive and negative, is invaluable. Negative feedback, specifically, is automatically categorized and tagged (e.g., “incorrect information,” “unclear response,” “missing information”). This tagged feedback, along with the relevant conversation logs, is then used to create a supplementary training dataset. The retraining process occurs weekly, incorporating this fresh feedback to refine the model’s responses.
Targeted Retraining Strategies
Once weak areas are identified, targeted retraining becomes crucial. This focuses resources on improving specific conversational flows or knowledge domains, maximizing the impact of retraining efforts.
- Identifying Weak Areas: Conversation logs are analyzed using natural language processing (NLP) techniques to identify recurring patterns of errors or low user satisfaction. For instance, if the chatbot frequently fails to correctly answer questions about a specific product feature, this area is flagged for improvement.
- Targeted Training Datasets: Small, focused datasets are created to address the identified weaknesses. For example, if the chatbot struggles with product feature X, a dataset of 50-100 questions and answers specifically addressing feature X is created. This ensures the retraining effort is efficient and effective.
- A/B Testing Retraining Strategies: Different retraining approaches (e.g., adding more data, adjusting model parameters) are A/B tested to determine the most effective method for improving performance in the identified weak areas. This data-driven approach ensures optimal resource allocation.
Adaptive Knowledge Base Integration
The knowledge base is the lifeblood of the chatbot. A mechanism for automatically integrating updates and user-generated content is essential for maintaining accuracy and relevance.
- Detecting Knowledge Base Changes: The system monitors the knowledge base for updates (e.g., using version control systems or APIs). Any change triggers a retraining process, ensuring the chatbot reflects the latest information. Retraining frequency depends on the update’s impact; major updates trigger immediate retraining, while minor updates might be incorporated in the weekly retraining cycle.
- Incorporating User-Generated Content: User-generated content from FAQs or community forums can be incorporated, but it undergoes a rigorous moderation and quality control process. This includes checking for accuracy, relevance, and appropriateness before integration into the knowledge base. This enriched knowledge base then triggers a retraining cycle.
- Dynamic Response Adjustment: User interaction data is continuously analyzed to detect shifts in user behavior or preferences. For example, if users frequently ask about a specific topic, the chatbot’s responses can be dynamically adjusted to provide more relevant and comprehensive information. This adaptive approach ensures the chatbot remains aligned with evolving user needs.
Ongoing Monitoring and Improvement Plan
A structured plan ensures consistent monitoring and improvement. This involves defining roles, responsibilities, reporting mechanisms, and documentation procedures. The table below illustrates a sample plan.
| Improvement Area | KPI | Target Value | Monitoring Frequency | Responsible Team |
|---|---|---|---|---|
| User Satisfaction | Average satisfaction score (1-5) | 4.5 | Weekly | Customer Success |
| Task Completion Rate | Percentage of tasks completed successfully | 95% | Daily | Engineering |
| Average Handling Time | Average time to resolve a query (seconds) | 30 | Daily | Engineering |
| Knowledge Base Accuracy | Percentage of accurate responses | 98% | Monthly | Content Team |
Security Considerations
Deploying an AI chatbot, especially one trained on a custom knowledge base, introduces several security risks that must be carefully addressed. Protecting both the sensitive information within the knowledge base and the privacy of user data is paramount. Neglecting these considerations can lead to data breaches, reputational damage, and legal repercussions.
Data Breaches and Unauthorized Access
Preventing unauthorized access to the knowledge base and user data is crucial. Robust authentication and authorization mechanisms are essential. This includes secure password management, multi-factor authentication (MFA), and role-based access control (RBAC). The knowledge base itself should be stored securely, potentially using encryption at rest and in transit. Regular security audits and penetration testing should be conducted to identify and address vulnerabilities.
Furthermore, data loss prevention (DLP) tools can help monitor and prevent sensitive information from leaving the system. Consider using a cloud provider with strong security features and compliance certifications. For example, implementing encryption at the database level, using AWS KMS for key management, and regularly patching the underlying infrastructure are key steps.
Protection of User Data and Privacy
User data privacy is paramount. Compliance with relevant regulations such as GDPR and CCPA is essential. This involves obtaining informed consent for data collection, providing transparency about data usage, and giving users control over their data. Data minimization should be practiced, collecting only the necessary data. Anonymization and pseudonymization techniques can further protect user privacy.
Regular privacy impact assessments (PIAs) should be conducted to identify and mitigate potential privacy risks. Consider implementing differential privacy techniques to add noise to aggregated data, preventing the identification of individual users. For example, a chatbot interacting with customer support data should only use anonymized identifiers to prevent the exposure of personally identifiable information (PII).
Secure Development Practices
Secure coding practices are fundamental to chatbot security. This includes using secure libraries, avoiding common vulnerabilities, and performing regular code reviews. Input validation and sanitization are critical to prevent injection attacks. Regular security updates and patches for the chatbot platform and underlying infrastructure are essential. Employing a secure development lifecycle (SDLC) that incorporates security considerations at every stage, from design to deployment, is crucial.
For instance, using a static analysis tool during the development process can help identify potential vulnerabilities before deployment.
Security Checklist for AI Chatbot Development and Deployment
A comprehensive security checklist is vital for ensuring a secure chatbot system. This checklist should cover the following key areas:
| Area | Checklist Item |
|---|---|
| Authentication & Authorization | Implement strong password policies and MFA. |
| Data Protection | Encrypt data at rest and in transit. |
| Vulnerability Management | Conduct regular security audits and penetration testing. |
| Privacy Compliance | Comply with relevant regulations (GDPR, CCPA, etc.). |
| Secure Development | Follow secure coding practices and use a secure SDLC. |
| Incident Response | Develop and test an incident response plan. |
Cost Optimization
Training and deploying an AI chatbot, while offering significant advantages, involves considerable financial investment. Understanding and managing these costs is crucial for ensuring the project’s long-term viability and return on investment. This section explores key cost drivers and provides practical strategies for optimizing expenses throughout the chatbot’s lifecycle.
Factors Contributing to Chatbot Costs
Several factors significantly influence the overall cost of developing and deploying an AI chatbot. These include the cost of data acquisition and preparation, the computational resources required for training and inference, the selection of AI models (with varying computational demands), the infrastructure choices (cloud vs. on-premise), the ongoing maintenance and updates, and the expertise needed for development and deployment. A comprehensive cost analysis should consider all these elements.
Strategies for Optimizing Training and Deployment Costs
Cost optimization necessitates a multifaceted approach. One crucial strategy involves careful data selection and preprocessing. Using smaller, high-quality datasets tailored specifically to the chatbot’s purpose can significantly reduce training time and computational expenses. Choosing the right AI model is equally vital; simpler models, while potentially offering slightly less accuracy, can be significantly more cost-effective than complex, resource-intensive models.
Furthermore, exploring open-source alternatives to proprietary software can also yield considerable savings. Finally, optimizing the chatbot’s architecture for efficiency, including minimizing unnecessary computations, can contribute to lower operational costs.
Managing Cloud Computing Costs for Chatbot Development
Cloud computing offers scalability and flexibility, but it’s essential to manage costs effectively. Strategies include utilizing spot instances (for less time-sensitive tasks), leveraging serverless computing to pay only for the actual compute time used, and optimizing resource allocation by right-sizing instances to match the chatbot’s demands. Regularly monitoring resource utilization and implementing automated scaling based on real-time demand helps avoid unnecessary expenses.
Consider using cost-optimization tools offered by cloud providers, which provide insights into usage patterns and suggest areas for improvement. For example, analyzing billing reports to identify peak usage times and adjusting resource allocation accordingly can lead to substantial savings. A hypothetical example: if a chatbot experiences high traffic only during specific hours, scaling down resources during off-peak times could significantly reduce monthly cloud bills.
Cost Analysis Framework for Chatbot Deployment Options
A robust cost analysis framework should compare different deployment options, including cloud-based solutions (AWS, Azure, GCP), on-premise servers, and hybrid approaches. The framework should consider:
- Initial setup costs: This includes hardware, software licenses, and initial configuration expenses.
- Recurring operational costs: These encompass cloud computing fees, maintenance expenses, and personnel costs.
- Scalability costs: How easily can the system handle increased traffic and data volume?
- Maintenance and updates: Factor in the costs associated with software updates, security patches, and ongoing maintenance.
By systematically evaluating these factors across different deployment options, businesses can make informed decisions that align with their budget and long-term objectives. For instance, a comparison between deploying on AWS versus using a managed chatbot platform would reveal differing cost structures, allowing for a data-driven choice. This framework helps avoid unexpected costs down the line.
Error Handling and Debugging
Building robust AI chatbots requires meticulous attention to detail, especially when it comes to handling errors during training and deployment. This section delves into common errors encountered while working with Rasa, a popular open-source framework for building conversational AI, and provides practical strategies for debugging and resolving them. We’ll cover various chatbot types, focusing on the challenges unique to Rasa’s architecture.
Common Errors During Chatbot Training and Deployment
Several error categories can arise during the lifecycle of a Rasa chatbot. Understanding these categories is crucial for effective troubleshooting. These errors can be broadly classified into data issues, model issues, deployment problems, and ambiguity handling challenges.
- Data Errors: These stem from problems with the training data itself.
- Insufficient Training Data: The model lacks enough examples to learn effectively, leading to poor generalization and inaccurate responses. Causes include a small dataset or an uneven distribution of intents and entities.
- Biased Data: The training data reflects existing biases, resulting in the chatbot exhibiting prejudiced behavior. Causes include skewed data representation or using data that reflects societal biases.
- Inconsistent Data: Contradictory or conflicting information in the training data confuses the model, hindering its ability to learn consistent patterns. Causes include errors in data entry or inconsistent labeling.
- Model Errors: These are problems inherent to the trained model itself.
- Low Accuracy: The chatbot frequently provides incorrect or irrelevant responses. Causes include insufficient training data, poor model architecture, or inappropriate hyperparameter settings.
- Hallucinations: The chatbot generates nonsensical or fabricated responses, often lacking grounding in the training data. Causes include overfitting, inadequate data, or insufficient context understanding.
- Lack of Context Understanding: The chatbot struggles to maintain conversation flow and fails to utilize previous turns appropriately. Causes include insufficient context features or an inadequate model architecture for handling context.
- Deployment Errors: These arise during the process of making the chatbot accessible to users.
- API Connectivity Issues: The chatbot fails to connect to necessary APIs or services. Causes include network problems, incorrect API credentials, or server-side errors.
- Scaling Problems: The chatbot struggles to handle a large number of concurrent users. Causes include insufficient server resources or inefficient code.
- Resource Exhaustion: The chatbot consumes excessive resources (CPU, memory, etc.), leading to slow performance or crashes. Causes include memory leaks, inefficient algorithms, or high user load.
- Ambiguity Handling Errors: The chatbot fails to resolve ambiguous user inputs correctly.
- Intent Misclassification: The chatbot incorrectly identifies the user’s intent. Causes include ambiguous user phrasing or insufficient training data for specific intents.
- Entity Extraction Errors: The chatbot fails to correctly extract relevant entities from user input. Causes include poor entity definitions or ambiguous user phrasing.
- Configuration Errors: These errors stem from mistakes in the Rasa configuration files.
- Incorrect Configuration: Errors in the `config.yml` or `domain.yml` files can lead to model training failures or unexpected chatbot behavior. Causes include typos, incorrect parameter values, or missing configurations.
- Version Mismatches: Incompatibilities between Rasa versions or dependencies can cause unexpected errors. Causes include using outdated libraries or incorrect dependency versions.
Debugging Methods and Resolution Strategies
Effective debugging involves a combination of preventative measures and reactive solutions. Here’s a table summarizing debugging methods for the error categories listed above:
| Error Category | Debugging Method 1 | Debugging Method 2 | Preventative Measures |
|---|---|---|---|
| Insufficient Training Data | Analyze data distribution with histograms using libraries like Matplotlib. | Inspect model training logs for metrics like precision and recall. | Gather more diverse and representative training data, focusing on edge cases and long-tail intents. |
| Biased Data | Analyze the data for overrepresentation or underrepresentation of specific groups. | Use bias detection tools and techniques to identify and mitigate bias. | Carefully curate the training data, ensuring diverse representation and removing biased samples. |
| Inconsistent Data | Manually review a sample of the training data for inconsistencies. | Use data validation techniques to identify and correct inconsistencies. | Establish clear data entry guidelines and implement data validation checks. |
| Low Accuracy | Examine the confusion matrix to identify misclassified intents or entities. | Analyze model predictions on a held-out test set. | Increase training data, adjust model hyperparameters, or consider a different model architecture. |
| Hallucinations | Analyze model predictions for nonsensical or fabricated information. | Improve data quality and context handling within the model. | Increase training data, improve data quality, add context features, and carefully tune hyperparameters. |
| Lack of Context Understanding | Examine the conversation history to identify points where context is lost. | Implement mechanisms for explicit context passing within the model. | Use context-aware model architectures, implement dialogue management techniques, and incorporate context features. |
| API Connectivity Issues | Check network connectivity and API credentials. | Inspect server logs for error messages. | Thoroughly test API connections, use robust error handling, and implement logging for debugging. |
| Scaling Problems | Profile the application to identify performance bottlenecks. | Implement load balancing and horizontal scaling strategies. | Optimize code for efficiency, utilize caching mechanisms, and employ appropriate scaling strategies. |
| Resource Exhaustion | Monitor resource usage (CPU, memory) during runtime. | Identify and address memory leaks or inefficient algorithms. | Optimize code for memory efficiency, implement resource limits, and use efficient data structures. |
| Intent Misclassification | Review user inputs and corresponding intent predictions. | Analyze the similarity between intents and adjust training data accordingly. | Improve intent definitions, use synonyms, and gather more data for ambiguous intents. |
| Entity Extraction Errors | Review user inputs and corresponding entity extractions. | Adjust entity definitions and add more training examples. | Refine entity definitions, use regular expressions for precise matching, and increase training data. |
| Incorrect Configuration | Carefully review the `config.yml` and `domain.yml` files for errors. | Consult the Rasa documentation for correct configuration parameters. | Use a configuration validation tool and follow the Rasa documentation for best practices. |
| Version Mismatches | Check Rasa and its dependencies versions for compatibility. | Use a virtual environment to manage dependencies. | Use a consistent version management system and ensure all dependencies are compatible. |
Scalability and Performance
Building a high-performing AI chatbot requires careful consideration of scalability and performance from the outset. A chatbot that struggles to handle increased user load will quickly become unusable, negating its potential benefits. This section details strategies for ensuring your chatbot can gracefully handle growth and maintain responsiveness even under peak demand.
Scaling Strategies
Several strategies exist to enhance chatbot scalability, broadly categorized as vertical and horizontal scaling. Vertical scaling involves increasing the resources of a single server (e.g., adding more RAM, CPU cores), while horizontal scaling involves distributing the workload across multiple servers. The optimal approach depends on factors such as budget, technical expertise, and expected growth rate.
- Vertical Scaling: This approach is simpler to implement initially, requiring fewer infrastructure changes. However, it has limitations. There’s a physical limit to how much you can upgrade a single server. Beyond this point, performance gains diminish, and the system becomes a single point of failure.
- Horizontal Scaling with Database Sharding: This involves partitioning the database across multiple servers. Each shard handles a subset of the data, improving read and write performance. This is effective for large datasets but introduces complexity in data management and query routing.
- Horizontal Scaling with Load Balancing and Caching: This distributes incoming requests across multiple servers using a load balancer (e.g., Nginx, HAProxy). Caching frequently accessed data (e.g., using Redis or Memcached) reduces database load and improves response times. This approach offers high scalability and fault tolerance but requires more complex infrastructure management.
Comparative Analysis of Scaling Strategies
| Strategy | Cost | Complexity | Performance | Advantages | Disadvantages |
|---|---|---|---|---|---|
| Vertical Scaling | Low (initially) | Low | Moderate (limited by hardware) | Simple to implement, less infrastructure | Limited scalability, single point of failure |
| Horizontal Scaling (Sharding) | Medium to High | High | High | Excellent scalability, high availability | Complex data management, potential for data inconsistencies |
| Horizontal Scaling (Load Balancing & Caching) | Medium to High | Medium | High | High scalability, fault tolerance, improved response times | Requires more infrastructure management |
Optimizing Response Time and Throughput
Optimizing the chatbot’s performance involves optimizing code, database queries, and network communication.
Code Optimization
Asynchronous processing, using techniques like asyncio in Python, allows the chatbot to handle multiple requests concurrently without blocking. This significantly improves throughput.“`pythonimport asyncioasync def process_request(request): # Process the request asynchronously await asyncio.sleep(1) # Simulate processing time return “Response to ” + requestasync def main(): tasks = [process_request(f”Request i”) for i in range(10)] results = await asyncio.gather(*tasks) print(results)asyncio.run(main())“`Using efficient algorithms (e.g., optimized search algorithms) also reduces processing time.
For example, replacing a linear search with a binary search can drastically reduce response time for large knowledge bases. The expected improvement depends on the specific algorithm and data size but can range from a few milliseconds to several seconds.
Database Query Optimization
Indexing database tables significantly speeds up query execution. Properly designed indexes allow the database to quickly locate relevant data without scanning the entire table. Query optimization techniques, such as using appropriate JOINs and avoiding full table scans, further improve performance. The improvement can range from 10x to 100x depending on the query and data size.
Network Communication Optimization
Minimizing network latency is crucial for fast response times. Using efficient protocols (e.g., gRPC instead of REST) and optimizing data transfer size can significantly improve performance. The improvement varies depending on network conditions but can range from a few milliseconds to several hundred milliseconds.
Handling Large Volumes of User Queries
Efficient queuing systems are vital for managing high volumes of user queries. These systems buffer incoming requests, ensuring that the chatbot processes them in an orderly manner, even during peak demand. Implementing rate limiting prevents system overload by restricting the number of requests from a single user or IP address within a specific time frame. Prioritizing critical queries (e.g., those from paying customers) ensures that important requests are processed promptly.
Monitoring KPIs such as response time, error rate, and throughput allows for proactive identification and resolution of performance bottlenecks.
Comparison of Queuing Systems
| Feature | RabbitMQ | Kafka |
|---|---|---|
| Message Persistence | High durability, supports various persistence mechanisms | High durability, configurable persistence levels |
| Scalability | Highly scalable, can handle millions of messages | Extremely scalable, designed for massive data streams |
| Throughput | High throughput, suitable for various message sizes | Extremely high throughput, optimized for large-scale data processing |
| Complexity | Moderate complexity, requires some administrative overhead | Higher complexity, requires more advanced configuration and management |
Performance Testing Plan
A comprehensive performance testing plan is essential to evaluate the chatbot’s scalability and responsiveness. This plan should include load testing, stress testing, spike testing, and endurance testing.
Load Testing
Target user load: 1000 concurrent users, 1000 requests per second. Duration: 1 hour. Tools: JMeter, k6.
Stress Testing
Gradually increase the user load beyond the expected capacity (e.g., 2000 concurrent users, 2000 requests per second) to identify breaking points.
Spike Testing
Simulate sudden surges in user traffic (e.g., a 10x increase in requests within a short period).
Endurance Testing
Assess system stability under sustained load (e.g., 1000 concurrent users, 1000 requests per second) for 24 hours.
Metrics
The following KPIs will be monitored:
- Average Response Time (Target: < 2 seconds)
- 99th Percentile Response Time (Target: < 5 seconds)
- Throughput (Target: > 1000 requests/second)
- Error Rate (Target: < 1%)
- CPU Utilization
- Memory Usage
User Interface Design

A user-friendly interface is paramount for a successful AI chatbot. Intuitive navigation, clear communication, and accessibility features are crucial for a positive user experience, regardless of the user’s technical skills or abilities. This section details the design considerations for our AI chatbot’s user interface, focusing on accessibility, error handling, and user feedback mechanisms.
User Interface Accessibility
Designing for accessibility ensures inclusivity and allows users with disabilities to interact effectively with the chatbot. We will adhere to WCAG (Web Content Accessibility Guidelines) standards to guarantee compatibility with assistive technologies like screen readers and keyboard navigation. Specific accessibility features include: keyboard navigation for all interactive elements; proper ARIA attributes and semantic HTML for screen reader compatibility; sufficient color contrast between text and background, adhering to WCAG AA compliance; and alternative text for all non-text content, such as images and icons.
The UI will be responsive, adapting seamlessly to various screen sizes (desktop, mobile, tablet) through a fluid design and flexible layout.
Clear and Concise Communication
Ambiguous phrasing can lead to user frustration and misinterpretations. Our UI will employ clear, concise language in prompts, responses, and error messages. For instance, instead of saying “There was a problem,” we’ll use specific error messages such as “Your input is too long. Please shorten your query.” or “The system is currently unavailable. Please try again later.”.
Visual cues, such as icons and color-coding, will be used strategically to enhance understanding. For example, a green checkmark could indicate a successful query, while a red exclamation mark could signify an error. Consistent visual language will be maintained throughout the user interface.
Positive User Experience and Feedback Mechanisms
Minimizing cognitive load is essential for a positive user experience. This will be achieved through a clean, uncluttered interface, intuitive navigation, and progressive disclosure of information. Progress indicators will provide feedback during processing, and clear feedback mechanisms will confirm user actions. For example, a confirmation message will appear after a successful query, while a loading spinner will indicate that the chatbot is processing the request.
User feedback will be collected through surveys and in-app feedback forms, allowing for iterative design improvements. User testing will involve usability studies with diverse participants, including users with disabilities, to identify areas for improvement.
User Interface Mock-up
The chatbot’s UI will be a single-page application, employing a conversational interface. The top section will display the chatbot’s logo and a brief description. Below this, a chat window will show the conversation history, with user inputs displayed in a light-grey speech bubble on the right, and chatbot responses in a dark-grey speech bubble on the left. A text input field at the bottom will allow users to type their queries, with a send button adjacent to it.
A small microphone icon will provide a speech-to-text option. The font will be a clear, sans-serif typeface with sufficient spacing for readability. A muted color palette will be used to minimize visual distractions. A loading indicator will appear below the input field while the chatbot is processing a request.
Interaction Flows
A successful query would involve the user typing a question, pressing “Send,” and seeing the chatbot’s response in the chat window. Error handling would involve displaying an appropriate error message in the chat window, guiding the user to correct their input. A multi-turn conversation would involve multiple exchanges between the user and the chatbot within the same chat window.
UX Details for Chat Window
Purpose and Functionality
Displays the conversation history between the user and the chatbot.
Input Fields
Text input field for user queries, “Send” button, microphone icon for speech-to-text.
Visual Elements
Dark-grey and light-grey speech bubbles for chatbot and user messages respectively, clear sans-serif font, sufficient spacing.
Feedback Mechanisms
Loading indicator while processing, confirmation messages after successful queries.
Navigation System
Single-page application; no navigation required.
Accessibility Considerations Table
| Feature | Description | Accessibility Implementation |
|---|---|---|
| Keyboard Navigation | Ability to navigate the UI using only keyboard. | All interactive elements must be accessible via keyboard. Tab order will be logical and intuitive. |
| Screen Reader Compatibility | Support for screen readers. | Proper ARIA attributes (aria-label, aria-describedby, etc.) and semantic HTML (headings, lists, etc.) will be used. |
| Color Contrast | Sufficient contrast between text and background. | WCAG AA compliance for color contrast ratios will be strictly followed. |
| Alternative Text | Text descriptions for images and icons. | Provide alt text for all non-text content. |
Error Handling Examples
If the chatbot does not understand the user’s input, it will display a message like: “I’m sorry, I didn’t understand your request. Could you please rephrase it?” If the system encounters an internal error, it will display a message like: “Oops! Something went wrong on our end. Please try again later.” In both cases, the UI will remain responsive, allowing the user to continue interacting.
Feedback Mechanisms
The UI will provide feedback through visual cues (loading indicators, checkmarks, exclamation marks), and textual messages confirming actions or indicating errors. Feedback will be provided immediately after an action or event, and its placement will be clear and unambiguous. Auditory cues will not be implemented initially, but could be considered in future iterations based on user feedback. Haptic feedback is not applicable to this web-based application.
Question & Answer Hub
What types of knowledge bases are suitable for this method?
This method works well with various knowledge bases, including FAQs, product manuals, internal wikis, and any structured or semi-structured data that can be converted into a suitable format for AI training.
How much data do I need to train an effective chatbot?
The required amount of data depends on the complexity of your knowledge base and the desired performance of your chatbot. More data generally leads to better performance, but the quality of the data is more important than quantity. A well-curated dataset of a few thousand examples can often be sufficient.
What if my knowledge base contains sensitive information?
Prioritize data security and privacy. Employ robust encryption methods, access controls, and anonymization techniques where appropriate to protect sensitive information throughout the entire process.
Can I integrate this chatbot with existing systems?
Yes, most chatbot platforms offer APIs and integration capabilities allowing seamless connection with CRM systems, messaging platforms, and other applications. The specific integration process depends on the chosen platform and your existing infrastructure.
How do I handle updates to my knowledge base after the chatbot is deployed?
Implement a system for continuous learning. Regularly update your knowledge base and retrain your chatbot model using new data. Consider using techniques like incremental learning to minimize retraining time and resource consumption.

